 Eseandre Mordi
Eseandre Mordi

Kuaishou's Kling Team unveiled HyDRA, a memory-based approach for dynamic video world models that preserves subject identity and motion continuity across occlusions and transitions. As reported by DailyPapers, the system directly tackles one of the most persistent problems in AI video generation - subjects that freeze, distort, or disappear once they move out of view.
The core challenge HyDRA addresses is one that existing AI video systems have consistently struggled with. Most current models treat scenes as largely static, losing track of objects the moment they exit the visible frame. When those objects return, the model essentially has to guess what they looked like, leading to jarring inconsistencies and broken continuity.
HyDRA Preserves 3 Consistency Layers Across Video Sequences
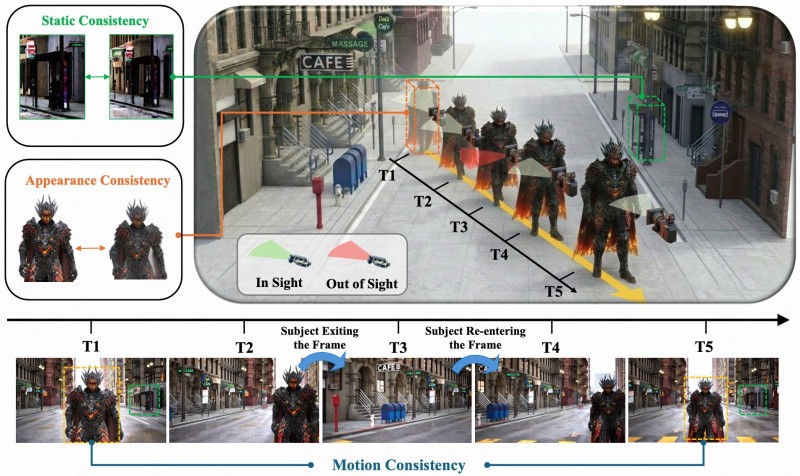
The architecture focuses on three distinct aspects of subject preservation that work together to maintain coherence throughout a sequence:
- Static consistency - retaining the subject's core visual identity regardless of frame position
- Appearance consistency - keeping textures, colors, and structural details stable across time steps
- Motion continuity - ensuring movement trajectories remain logical and uninterrupted
By maintaining all three elements simultaneously, HyDRA ensures that subjects remain coherent throughout a sequence, even across occlusion or transitions between scenes.
The ability to remember and reconstruct subjects consistently is likely to define the next generation of realistic video synthesis - not just generating individual frames in isolation.
This approach aligns with broader improvements in Kuaishou's Kling AI systems, which are increasingly designed to model temporal dynamics rather than simply produce visually convincing individual frames. The accompanying architectural diagram illustrates how a subject is tracked across multiple time steps, maintaining consistent appearance and motion even when temporarily out of sight.
HyDRA Fits a Wider Push for Reliable AI Video Generation
Similar progress in AI video efficiency has been emerging across the field. VDROP Cuts AI Video Latency by 74% Without Changing Model Architecture demonstrated how significant performance gains are possible without restructuring existing pipelines, while AI Model Generates 5-Second Video in 2 Seconds on H100 highlighted the accelerating pace of generation speed improvements across the industry.
Maintaining continuity across time - not just generating individual frames - is becoming central to progress in AI video modeling.
Together, these developments point to a clear shift in priorities: the field is moving beyond raw visual quality toward temporal reliability and subject coherence as the defining benchmarks for next-generation video synthesis.
 Eseandre Mordi
Eseandre Mordi


