 Eseandre Mordi
Eseandre Mordi

Researchers from Sichuan University, EPIC Lab at Shanghai Jiao Tong University, and Zhejiang University have developed V²Drop, a method that speeds up inference in large vision-language models (LVLMs) by selectively removing visual tokens that carry little new information. As 机器之心 JIQIZHIXIN reported, the technique targets the core inefficiency in how these models process visual data - and does it without touching the model itself.
How V²Drop Reduces Latency in Vision-Language Models
The method works by measuring variation in each token across adjacent transformer layers. Tokens that change very little between layers are contributing minimal new information to the model's understanding - so V²Drop drops them during inference.
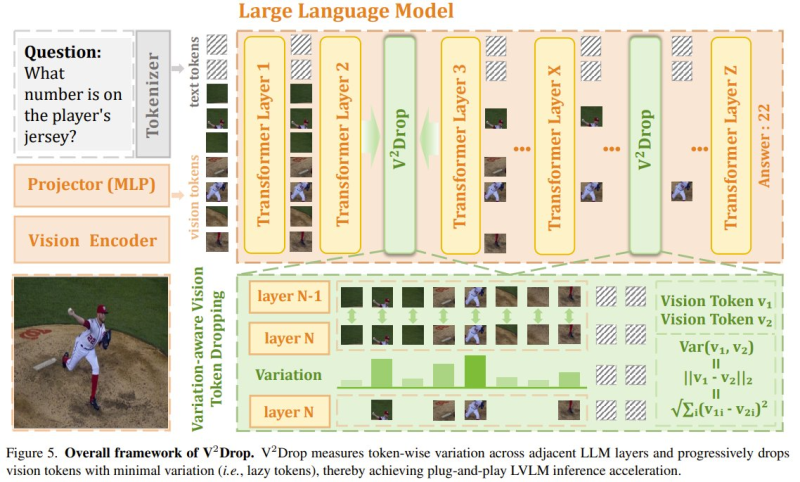
The result is fewer tokens processed per forward pass, which directly translates to faster generation times. This approach shares common ground with research on AI agent memory infrastructure, where selective retention of relevant context is equally central to performance.
Tokens that show minimal variation across transformer layers carry redundant information and can be removed without degrading the model's output quality.
Crucially, this happens without any modification to the underlying LVLM architecture. V²Drop plugs directly into existing pipelines, making it a practical option for teams looking to cut costs or latency on deployed models. The system's variation-aware mechanism is applied dynamically at inference, not baked into training.
V²Drop Performance: 98.6% Accuracy Retained on Video Tasks
The numbers are notable, especially on video workloads. Cutting latency by nearly three quarters while keeping 98.6% of original performance suggests the method is well-calibrated - it identifies genuinely redundant tokens rather than trimming tokens that still carry meaning. Image tasks see a more moderate speedup (31.5%) with slightly higher performance loss (6%), which is consistent with the fact that single images carry denser visual information per token than video frames, where temporal redundancy is much higher.
Video-based inference is particularly well-suited to token dropping because adjacent frames share substantial visual content - variation between layers is naturally low for many tokens.
These results position V²Drop alongside a broader class of inference optimization techniques gaining traction as real-time applications demand more from deployed models. Developments like Claude Opus 4.6 generating complex applications underscore how much pressure modern deployments put on inference pipelines - making efficiency gains at the token level increasingly valuable.
Why Token-Level Optimization Matters for AI Efficiency in 2025
The efficiency push in AI is no longer just about training costs. As models get deployed in video analysis, live transcription, and high-resolution image understanding, inference latency becomes the practical bottleneck. Techniques like V²Drop offer a path forward that doesn't require scaling up hardware or retraining models on new data.
The broader shift in AI development is toward squeezing more out of existing architectures - not just building larger ones.
This aligns with parallel developments across the industry. MIT research on AI deception cases reflects a growing focus on how AI systems behave under real-world conditions - not just benchmark performance. V²Drop fits into this picture as a concrete, deployable answer to one of the most pressing questions in applied AI: how to make powerful models fast enough to actually use.
The technique is particularly relevant for teams working on video-heavy applications where high-resolution inputs create significant token volumes. By addressing the problem at the token level rather than the model level, V²Drop keeps the solution lightweight and architecture-agnostic - a practical trait in a field where model architectures continue to evolve rapidly.
 Eseandre Mordi
Eseandre Mordi


