 Saad Ullah
Saad Ullah

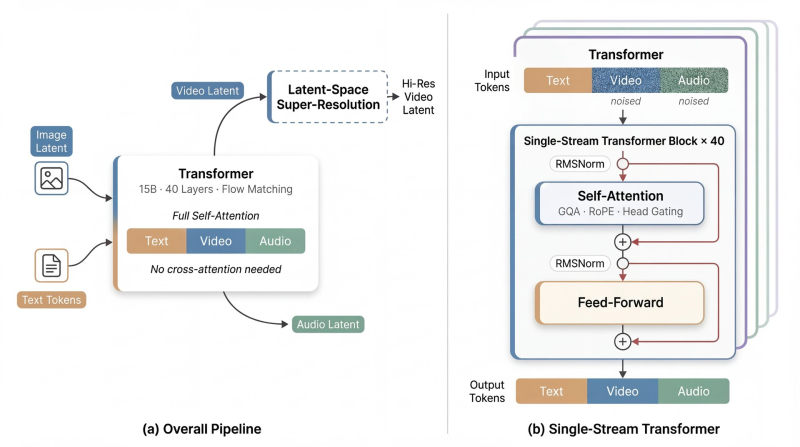
A new multimodal AI system called daVinci-MagiHuman can produce text, video, and audio from a single unified Transformer architecture. The model packs 15 billion parameters into a single-stream design with full self-attention across all modalities, cutting out the cross-attention mechanisms that typically add complexity to systems like this.
One Transformer Handles Text, Video, and Audio Simultaneously
The architecture stacks 40 Transformer layers that jointly process text tokens, video latents, and audio latents in a shared pipeline. Rather than routing different data types through separate specialized modules, everything runs through the same attention structure. A latent-space super-resolution module then converts compressed representations into higher-resolution outputs. The result is a noticeably cleaner design compared to most multimodal systems that rely on parallel or cascaded processing streams.
80% Win Rate Over Ovi 1.1 at 2-Second Generation Speed
On the performance side, the model generates 5 seconds of 256p video in roughly 2 seconds on Nvidia H100 hardware. It also reports an 80% win rate against Ovi 1.1, suggesting the speed gains do not come at the cost of output quality. For context on how far unified video AI has come, AI breakthrough trains on 250,000 film clips to fix scene transitions shows what large-scale video datasets can do for generation consistency.
The approach fits a broader trend in multimodal research. As covered in AI model introduces multimodal video-audio generation, the field is steadily moving toward architectures that handle multiple content types in one pass rather than chaining separate models. Meanwhile, Claude Opus 4.6 generates a 10,000-line video editing application, showing that modern AI is also expanding what it can build around video, not just generate.
The daVinci-MagiHuman release adds concrete evidence that simplified Transformer designs can compete on both speed and quality. If H100 hardware can push out near-real-time video at this parameter scale, the gap between research prototypes and production-ready multimodal tools is closing faster than expected.
 Saad Ullah
Saad Ullah


