 Eseandre Mordi
Eseandre Mordi

Huawei Technologies and Shanghai Jiao Tong University have developed HyperOffload, a compiler-assisted framework built to tackle one of the most persistent bottlenecks in large language model inference: memory. As reported by 机器之心 JIQIZHIXIN, the system doesn't just patch existing memory handling - it rethinks it entirely by folding memory access directly into the computation process.
The key insight behind HyperOffload is deceptively simple: rather than reacting to memory pressure as it happens, the framework treats remote memory access as a first-class part of the computation graph.
Instead of handling memory transfers locally, HyperOffload introduces a global planning mechanism that predicts data needs and schedules transfers ahead of time.
That shift allows it to globally schedule data transfers in advance, so computation and memory operations can run in parallel. The result is that latency gets hidden rather than stacked, and the system runs more efficiently without sacrificing output quality.
How HyperOffload Reduces LLM Memory Pressure by 26%
According to the technical report, this approach reduces peak device memory usage by up to 26% during LLM inference while keeping end-to-end performance intact. That's a meaningful number in an environment where memory constraints routinely determine what models can and can't run on a given piece of hardware.
Similar ideas are taking hold elsewhere in the industry - for instance, SpecDiff2 achieves a 55% speed boost in LLM inference through a comparable focus on execution efficiency.
This allows continuous computation without delays caused by memory bottlenecks, improving utilization of hardware resources across the board.
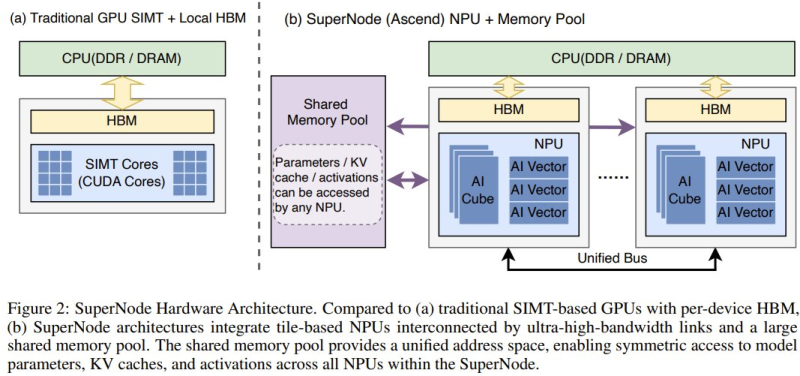
The framework specifically targets emerging SuperNode architectures - configurations where multiple processing units share a large memory pool connected by high-bandwidth links. In those environments, traditional local memory handling becomes a liability. HyperOffload replaces it with a predictive, globally coordinated scheduler that keeps compute units busy and avoids the idle cycles that typically eat into efficiency.
LLM Memory Optimization as an Industry-Wide Priority
The HyperOffload research reflects something broader happening across AI infrastructure. As language models grow in size and ambition, the hardware they run on is being pushed to its limits - and memory is consistently where things break down first. Teams across the industry are developing increasingly sophisticated approaches to the problem, including layered AI agent memory 4-layer infrastructure that handles different types of state at different levels of the stack.
As AI systems demand more resources, solutions that optimize memory usage without sacrificing performance are becoming increasingly critical.
That pressure isn't abstract. The scale of demand for efficient AI systems is visible in metrics like OpenAI revenue hitting $20B amid compute growth - a figure that underscores just how much infrastructure is being consumed by modern AI deployments. Frameworks like HyperOffload matter not just as research milestones, but as practical tools for making that infrastructure go further.
 Eseandre Mordi
Eseandre Mordi


