 Eseandre Mordi
Eseandre Mordi

⬤ SpecDiff-2 is making waves for dramatically improving how fast large language models generate text. This new approach swaps out the traditional autoregressive drafter used in speculative decoding with a discrete diffusion model. Rather than cranking out tokens one by one, SpecDiff-2 drafts entire blocks of tokens at once using just a handful of denoising steps.
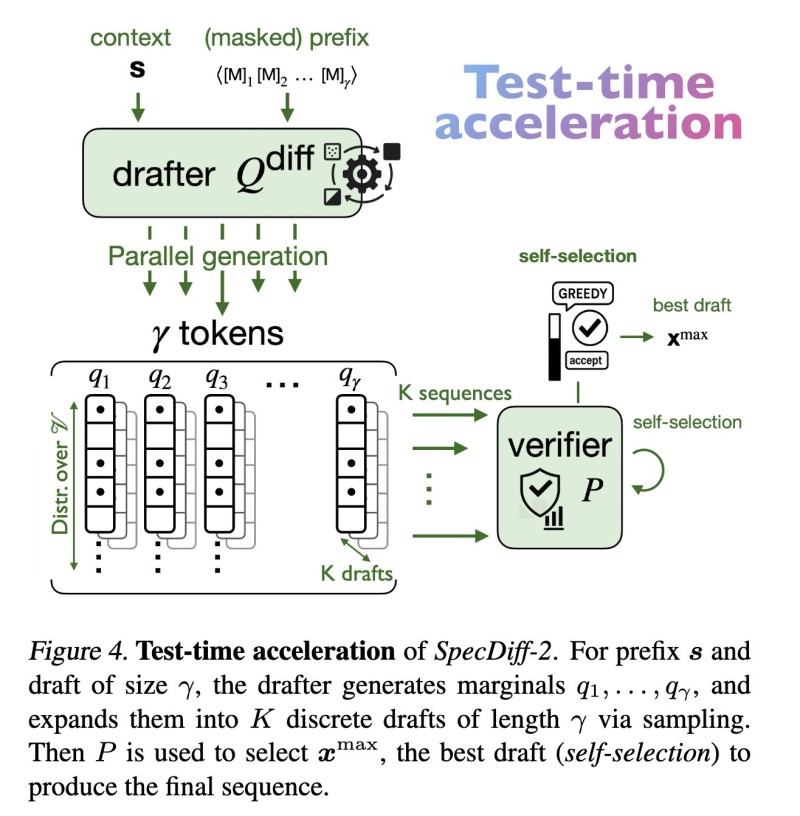
⬤ Here's how it works during inference: the system takes a prefix and uses its diffusion-based drafter to create probability distributions across a block of γ tokens. These get expanded into K candidate drafts—all happening in parallel through sampling instead of the usual step-by-step process. A verifier model then looks at these candidate sequences and picks the winner through self-selection. The real efficiency gain comes from how the drafting cost depends mostly on diffusion steps, not on how long the generated block is.
⬤ The performance numbers are impressive. SpecDiff-2 delivers speedups up to 5.5× compared with standard decoding methods while producing exactly the same final outputs. It also cranks out 55 percent more tokens per second than previous speculative decoding approaches. These gains showed up consistently across reasoning tasks, coding challenges, and math problems—areas where slow inference typically creates bottlenecks.

⬤ This matters because inference efficiency has become the make-or-break issue for deploying large language models in real applications. Faster decoding means lower latency, better throughput, and reduced compute costs. By proving that discrete diffusion can replace autoregressive drafting without changing what the model actually says, SpecDiff-2 opens up a promising path forward for inference optimization. If this catches on more widely, it could reshape how the next generation of language models gets built and rolled out in both research labs and production systems.
 Eseandre Mordi
Eseandre Mordi


