 Usman Salis
Usman Salis

OpenAI's latest reasoning models have achieved impressive results on one of the industry's most challenging benchmarks. The GPT-5.4 and GPT-5.4 Pro models are setting new standards in abstract reasoning capabilities, though these advances come with significant differences in computational costs.
GPT-5.4 Models Lead ARC-AGI-2 Performance Rankings
OpenAI's newest reasoning models, GPT-5.4 and GPT-5.4 Pro, have posted strong results on the ARC-AGI-2 benchmark, a test designed to measure abstract reasoning abilities in artificial intelligence systems. According to data highlighted by ARC Prize, GPT-5.4 achieved a score of 74.0%, while GPT-5.4 Pro reached 83.3%, placing both models among the top performers currently recorded on the benchmark. The evaluation also showed notable differences in inference cost between the two versions of the model.
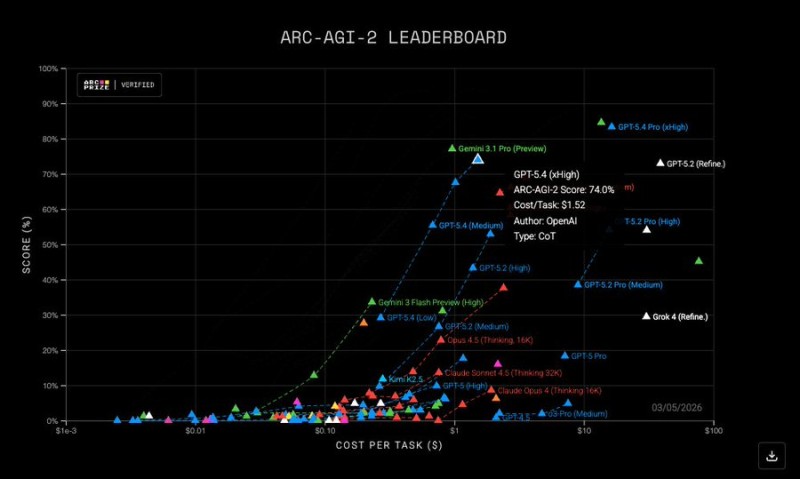
The ARC-AGI-2 benchmark is widely used in AI research to evaluate a system's ability to solve unfamiliar reasoning tasks rather than relying on memorized patterns. The leaderboard chart compares accuracy scores against the estimated cost per task for a wide range of large language models. In this evaluation, GPT-5.4 completed tasks at roughly $1.52 per task, while GPT-5.4 Pro required approximately $16.41 per task, reflecting the additional computational resources needed for the higher-capacity model.
Cost vs Performance Trade-offs in Modern AI Systems
The leaderboard shown in the chart also includes competing models from multiple AI developers, including systems from Google, DeepSeek, and other large language model families. GPT-5.4 Pro appears near the top of the performance scale, with accuracy levels significantly higher than many competing models plotted on the cost-versus-performance chart. Research discussions around the benchmark highlight how ARC-AGI-2 is designed to stress-test reasoning efficiency and generalization capabilities across different AI architectures.
These benchmark results illustrate the ongoing competition among major AI developers as companies continue to push improvements in reasoning performance and model efficiency. OpenAI's latest models are part of a broader sequence of upgrades across the GPT series, including earlier developments such as the GPT-5.3 Codex scoring 79.3 on WeirdML Benchmark, both of which highlight rapid progress in reasoning and coding benchmarks across the AI industry.
 Usman Salis
Usman Salis


