 Eseandre Mordi
Eseandre Mordi

⬤ New benchmark data shows GPT-5.4 has overtaken the human baseline in computer-use tasks. The model scored 75.0% against the human reference of 72.4%, a meaningful milestone for AI systems built to autonomously navigate software interfaces and carry out multi-step digital workflows. The result is part of a wider push at OpenAI, covered in OpenAI rolls out GPT-5.4 Thinking with 92.8% on GPQA Diamond.
⬤ On WebArena-Verified, which simulates real-world browser tasks, GPT-5.4 reached a 67.3% success rate using both DOM-based and screenshot-based methods, edging past GPT-5.2's 65.4%. The gap widens further on Online-Mind2Web: GPT-5.4 hit 92.8% using screenshot-based observations, well ahead of the 70.9% posted by ChatGPT Atlas Agent Mode on the same test.
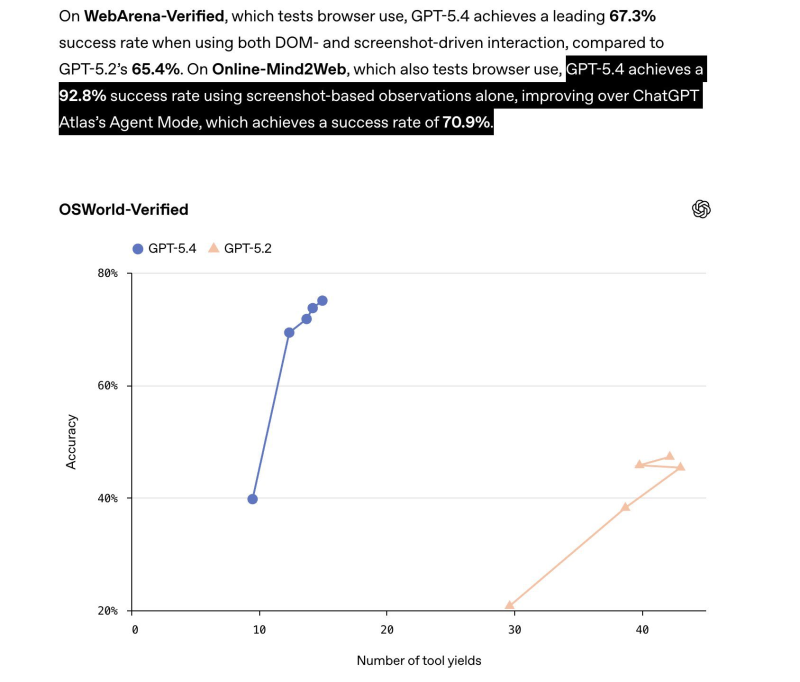
⬤ OSWorld-Verified results tell a similar story: GPT-5.4 exceeded 70% accuracy across several operating-system-level task scenarios and consistently outperformed GPT-5.2 across multiple tool-yield settings. Comparable progress in GUI automation has been documented in Alibaba MobileAgent v3.5 achieving a 56.5 score on OSWorld with multiplatform support.
⬤ Taken together, these numbers point to a structural shift. AI models are moving past static question-answering into active participation in real digital environments. Advances in memory architecture and agent design are accelerating the transition, as explored in AI memory evolution: 10x efficiency gains as RAG systems become obsolete. The computer-use ceiling, once set by human performance, has now been cleared.
 Eseandre Mordi
Eseandre Mordi


