 Usman Salis
Usman Salis

The Allen Institute for AI has launched OLMo Hybrid, a new open-weight language model that challenges the dominance of pure transformer architectures. The 7B-parameter model blends standard attention mechanisms with linear recurrent neural network layers, targeting better efficiency without sacrificing accuracy. This release fits into a broader architectural shift happening across the AI industry, similar to NVIDIA's Nemotron-3 Nano launch on Amazon Bedrock.
Half the Training Data, Better Long-Context Results
One of OLMo Hybrid's most striking claims is efficiency: the model reaches comparable accuracy to Allen AI's earlier transformer models using roughly half the training data. Long-context performance saw a sharp improvement as well, with benchmark scores rising from 70.9% to 85.0%.
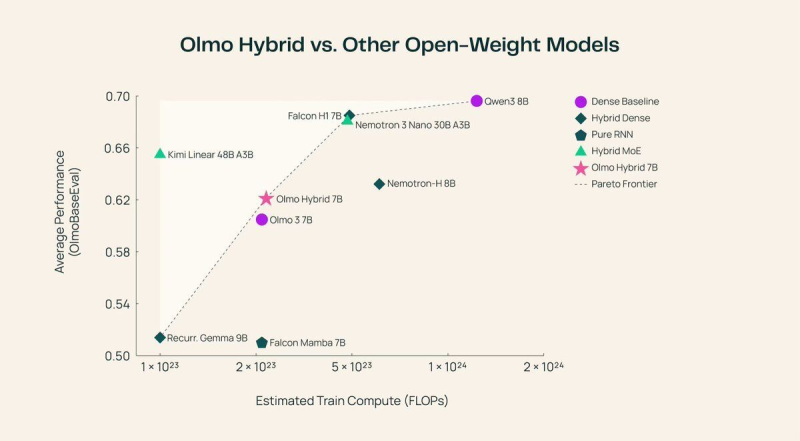
The model is fully open-weight, offering base, fine-tuned, and aligned versions for developers building long-context applications. The race among open models is heating up, as benchmark comparisons show - Falcon H1 7B recently scored 16 on the intelligence index among 7B models.
A 3:1 Layer Pattern That Cuts Compute Costs
The core innovation is a 3:1 layer ratio: three recurrent layers handle the bulk of sequence processing, followed by a single attention layer that refines the output. This design reduces reliance on expensive full attention operations while preserving precision where it matters most. Performance benchmarks place OLMo Hybrid 7B near the Pareto frontier when measuring average accuracy against estimated training compute. The model holds its own against systems like Qwen3 8B, Nemotron-H 8B, Falcon H1 7B, and Kimi Linear 48B A3B. Meanwhile, AI research continues expanding into physical systems as well, with projects like China Southern Power Grid testing the Unitree G1 robot with the BrainCo Revo2 hybrid hand pointing to the growing reach of AI beyond language tasks.
 Usman Salis
Usman Salis


