 Usman Salis
Usman Salis

⬤ Vision-language model development accelerates as researchers trial Chain-of-Visual-Thought, a new method that sharpens the way models read detailed images. The method alters the model's handling of visual data - blending ordinary text tokens with continuous visual tokens inside the reasoning steps. The model therefore thinks in small, exact visual pieces that register appearance, structure, depth and edges.
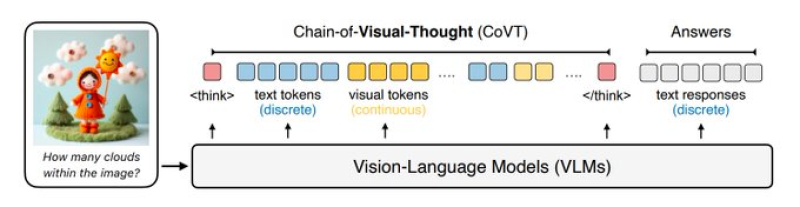
⬤ The framework follows one sequence - the model receives a prompt, produces mixed text and visual tokens while it reasons then outputs a plain text answer. Because continuous visual tokens sit inside this chain, models like Qwen2.5-VL plus LLaVA build a richer inner view of the image. Experiments show that the method raises visual reasoning scores by three to sixteen percent on more than ten benchmarks that cover recognition, spatial interpretation and multi-step visual analysis.
⬤ Those gains signal a broader move in multimodal AI toward clearer, structured reasoning. Earlier vision language models often stumble over small visual details or scenes that contain many objects - Chain-of-Visual-Thought eases this problem - supplying a steadier flow of visual information. The result is a model that analyses shapes, counts objects, understands layout and detects small details with steadier accuracy but also fewer errors.

⬤ The advance achieved with Chain-of-Visual-Thought indicates that stronger visual reasoning may power the next generation of multimodal AI systems. Improved inner processing creates opportunities in robotics, automation and real-world image analysis that demand reliability. As visual reasoning continues to strengthen, this method could turn into a core component for building vision language models that scale yet keep high accuracy.
 Usman Salis
Usman Salis


