 Eseandre Mordi
Eseandre Mordi

⬤ Teams from the University of Hong Kong and Adobe Research just dropped Self-E—a self-evaluating training framework that's changing how text-to-image models work. Here's what makes it different: the model actually critiques and improves its own work as it goes, basically becoming its own teacher. This solves a major headache with current diffusion and flow-based models, which typically fall apart when you try to speed things up by cutting down the generation steps.
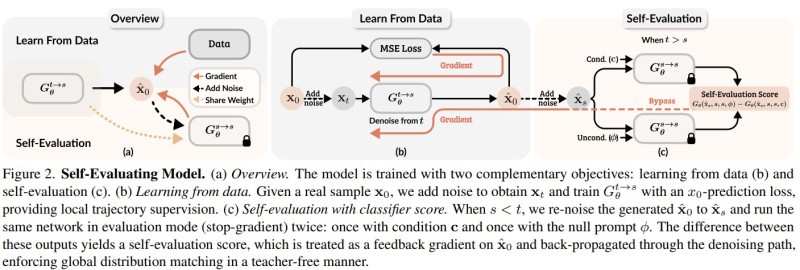
⬤ Self-E trains on two fronts simultaneously: learning from real data and evaluating itself. During data learning, it adds noise to actual images and uses x₀-prediction loss for trajectory guidance. But here's where it gets interesting—in the self-evaluation phase, the model takes its own generated output, adds noise back to it, then runs it through both conditional and unconditional settings using the same network in evaluation mode. The gap between these outputs creates a self-evaluation score that feeds back into the system, refining the denoising process without needing an external teacher model.
⬤ This self-evaluation setup delivers strong results whether you're running 2 steps or 200. At the low end, Self-E beats other flow-based generators on image quality while using fewer iterations. At higher step counts, it matches top-tier models—proving you're not sacrificing quality for speed. The same model adapts on the fly to different computational budgets and use cases, which is pretty much unheard of.

⬤ Self-E fits into a bigger shift toward teacher-free and self-supervised training in generative AI. Instead of relying on external classifiers, it uses internal feedback to match global distributions, making it more scalable and flexible. These kinds of advances could speed up how generative models get integrated into creative software and content production, where the balance between speed, cost, and quality matters more than ever.
 Eseandre Mordi
Eseandre Mordi


