 Usman Salis
Usman Salis

⬤ Claude AI users behave very differently after six months on the platform. Anthropic's Economic Index reveals a consistent behavioral shift: the longer someone uses Claude, the more they lean on it for professional, high-skill work and the less they treat it as a casual chat tool. The data suggests the platform is graduating from a curiosity into real workplace infrastructure.
⬤ Veteran users with six or more months of experience log roughly 10% fewer personal interactions and submit noticeably more complex prompts. Task success rates reach 73.1% for this group, versus 66.7% for newer users, a controlled gap of 3 to 4 percentage points. Work-related usage climbs from 41.6% to 48.9% while personal use slides from 44.3% to 40.3%. That professional pull is getting stronger as Anthropic's Claude Code Review cuts AI coding bottlenecks to under 20 minutes, giving teams a concrete reason to build Claude into their daily workflow.
Work-related usage rises from 41.6% to 48.9% among experienced users, while task success rates reach 73.1%.
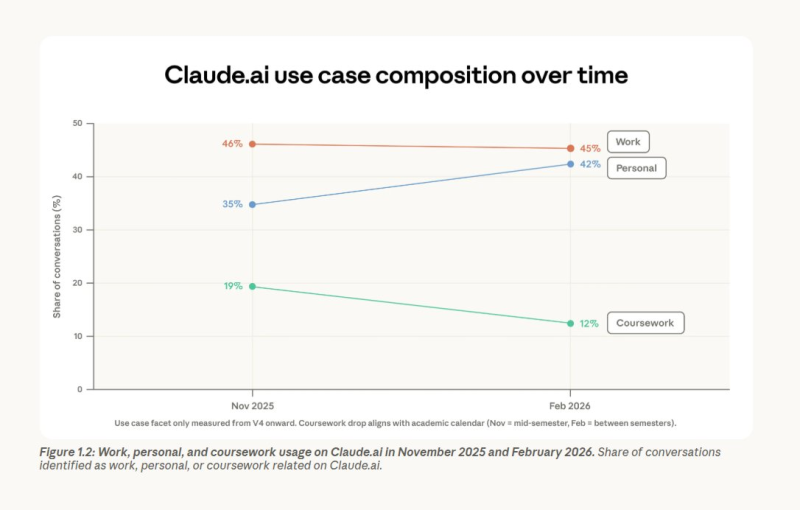
⬤ Zooming out to the full platform, the query mix has changed sharply. Personal use jumped from 35% to 42%, while coursework fell from 19% to 12% by early 2026. Work holds near 45%. Conversations are also spreading across more use cases, with the top 10 categories dropping from 24% to just 19% of total volume. Coding remains dominant at around 35%, though more of that work is now flowing through API integrations rather than the chat interface. The wider API race is heating up too, with Kimi K2.5 now live across 8 API providers and posting a 330-token-per-second speed gap between the fastest and slowest endpoints.
⬤ Geography tells two different stories at once. Inside the US, Claude's user base is spreading: the top five states' share dropped from 30% to 24%, a sign of broader domestic adoption. Globally, usage is actually concentrating, with the top 20 countries raising their combined share from 45% to 48%. The competitive pressure behind these numbers keeps growing, and benchmarks are becoming a battleground. GPT-5.4 scores 77.7 on WeirdML but trails Claude Opus 4.6 by a thin margin, a result that shows just how tight the gap between top models has become.
 Usman Salis
Usman Salis


