 Peter Smith
Peter Smith

Not all API endpoints are created equal — and Kimi K2.5 is making that very clear. As the model expands to more infrastructure platforms, the real-world performance gap between providers is growing hard to ignore.
Kimi K2.5 Reaches 8 Providers — And the Numbers Tell a Big Story
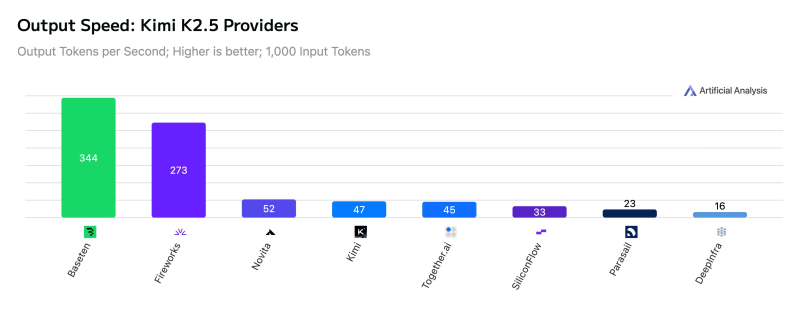
Moonshot AI's Kimi K2.5 is quietly becoming one of the more widely deployed open-weights models in the API ecosystem. Currently ranked #2 among open-weights models with a score of 47 on the Artificial Analysis Intelligence Index, it's earned a reputation as a go-to option for coding agents — thanks to strong reasoning and solid tool-use capabilities. Now, it's live across eight API providers, and the performance differences between them are anything but minor.
On raw output speed, Baseten sits at the top with 344 tokens per second, followed by Fireworks at 273 tokens/s. From there, the numbers drop sharply — Novita hits 52 tokens/s, Kimi's own endpoint lands at 47 tokens/s, and the slowest provider in the group manages just 16 tokens/s. That's a spread of roughly 330 tokens per second across the ecosystem, which is enormous for latency-sensitive applications.
Infrastructure choice affects real-world usability — differences in throughput, latency, and pricing are shaping deployment decisions.
Latency and Pricing: Where the Real Deployment Decisions Get Made
Speed isn't the only variable worth watching. On time-to-first-answer-token (TTFAT), Baseten again leads at 6.5 seconds, with Fireworks close behind at 7.7 seconds. Novita AI trails at 39.4 seconds. For time-to-first-token (TTFT) — often more relevant for interactive use cases — Fireworks jumps to first place at just 0.36 seconds, followed by Together AI at 0.49 seconds and Baseten at 0.72 seconds.
On the pricing side, DeepInfra offers the most competitive rates at $0.45 per million input tokens and $2.25 per million output tokens. Most providers in the group support a 256k token context window, though Baseten caps at 231k. Seven of the eight providers support multimodal inputs.
As Kimi K2.5 adoption grows, these differences are increasingly shaping where teams build — especially for coding agents and automated workflows where latency and throughput directly affect product quality.
 Peter Smith
Peter Smith


