 Usman Salis
Usman Salis

Fresh benchmark results reveal a clear winner in the race to deliver Z.ai's GLM-4.6 reasoning model: Baseten has pulled ahead of the pack with impressive speed metrics that leave competitors trailing. The data shows how critical infrastructure optimization has become in the world of open AI deployment.
Baseten Leads the Performance Rankings
Recent benchmark data from Artificial Analysis compared how major cloud providers handle GLM-4.6, an open-weight reasoning model built by Z.ai in collaboration with MIT. The results paint a clear picture of Baseten's technical edge.
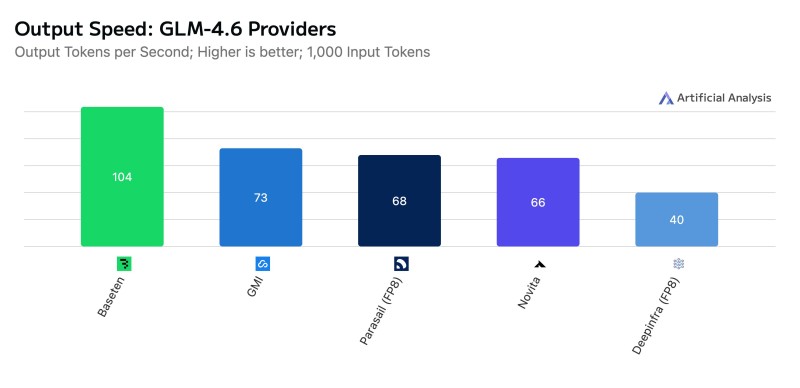
Baseten clocked in at 104 tokens per second for output speed, leaving GMI at 73 t/s, Parasail (FP8) at 68 t/s, Novita at 66 t/s, and Deepinfra (FP8) at 40 t/s in the dust. That's nearly 50% faster than its nearest rival, a gap that matters tremendously for real-world applications like agentic coding and automated analysis where every millisecond counts.
Beyond raw throughput, Baseten also recorded the quickest time-to-first-answer token at 19.4 seconds compared to GMI's 28.4 seconds. For reasoning models, this metric matters more than the standard time-to-first-token because it marks when actual reasoning output begins, not just when the model starts generating text.
Pricing Stays Tight Across Providers
Despite the performance differences, pricing remains remarkably consistent across the board:
- Deepinfra: $0.6/$1.9 per million tokens (input/output)
- GMI: $0.6/$2.0
- Parasail: $0.6/$2.1
- Novita & Baseten: $0.6/$2.2
This uniformity signals a maturing market where speed, reliability, and infrastructure quality drive differentiation rather than price wars. Every provider supports the full 200,000-token context window needed for complex reasoning tasks and offers tool-calling capabilities, with JSON mode available on most platforms.
Why GLM-4.6 Matters
GLM-4.6 belongs to a new wave of open reasoning models designed for step-by-step problem solving, code analysis, and complex decision-making. It sits alongside models like DeepSeek V3.2 Exp and Qwen-3-235B-2507, representing the cutting edge of publicly available reasoning AI.
What these benchmarks really show is that infrastructure now shapes user experience as much as the model itself. As open-weight models close the gap with proprietary systems like GPT-4 and Gemini, how efficiently a model runs matters just as much as how smart it is.
 Usman Salis
Usman Salis


