 Marina Lyubimova
Marina Lyubimova

⬤ Fresh research on neural network behavior has appeared in the AI community. It shows that models trained for completely different tasks appear to share low dimensional weight subspaces. The evidence comes from principal component analysis of weight matrices taken from Mistral-7B LoRAs, 500 Vision Transformers and 50 LLaMA-8B models. The eigenvalue plus explained-variance curves fall sharply - only a few principal directions explain most of the variation across those architectures.
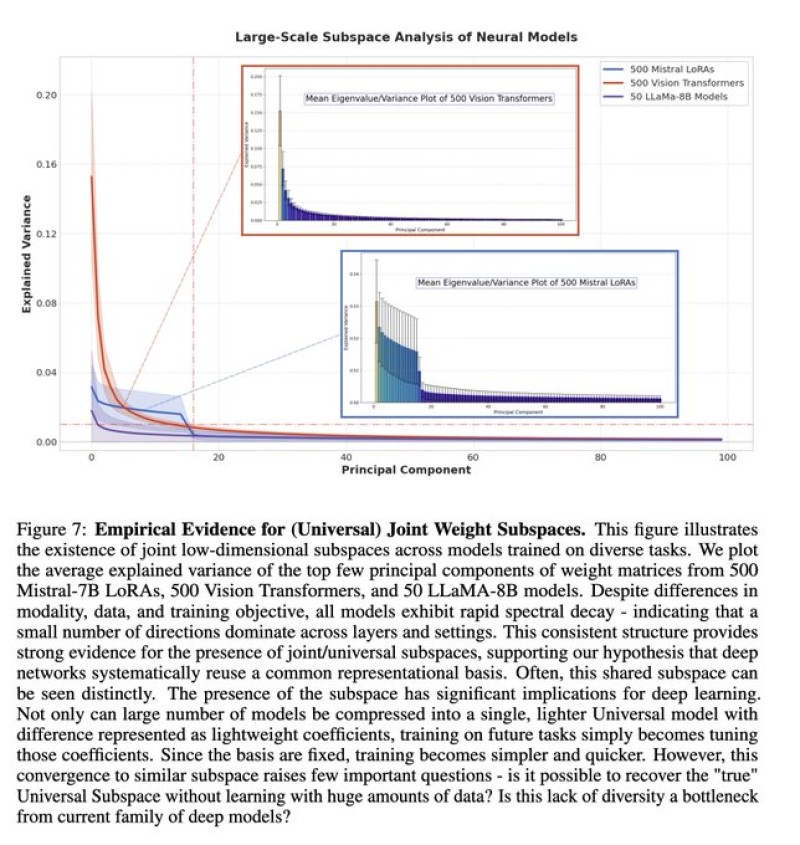
⬤ Every model examined displays similar structural patterns even though it handles different data types and pursues different training goals. This regularity implies that deep networks operate inside a shared representational framework. Critics note that Mistral-7B but also LLaMA-8B differ little in architecture - they give only weak support for the claim that the pattern is universal. LoRA variants help but do not cover the full range of model designs.
⬤ A stronger test would include models like Xiaomi MiMo, Qwen, GLM or MoE-based systems, because those differ markedly in structure, parameterization as well as training. If neural networks truly rely on shared low dimensional structures training efficiency, fine tuning speed and model compression would all improve. Relying on closely related models prevents definitive statements.

⬤ For the AI industry, this debate highlights the tension between exciting theoretical findings or the requirement for rigorous validation across architectures. If joint weight subspaces appear across a wider model family scaling laws, compute costs and model compatibility may need to be rethought. Until broader testing occurs, the discussion illustrates both the promise also the open questions about how deep learning functions beneath the surface.
 Marina Lyubimova
Marina Lyubimova


