 Usman Salis
Usman Salis

⬤ Resemble AI unveiled Chatterbox-Turbo, a 350 million parameter open-source text-to-speech model built for real-time voice agents with sub-200 millisecond latency. The model runs on a single GPU, including consumer-grade hardware, and supports CPU execution plus Apple M-series processors. It's designed to deliver low-latency voice synthesis without massive infrastructure requirements.
⬤ Chatterbox-Turbo cuts text-to-speech compute costs through key architectural updates. The 350M parameter design needs less VRAM, while the decoder now runs in a single pass instead of ten—removing a major performance bottleneck. These changes enable real-time performance at scale for live voice agents, narration, and interactive systems.
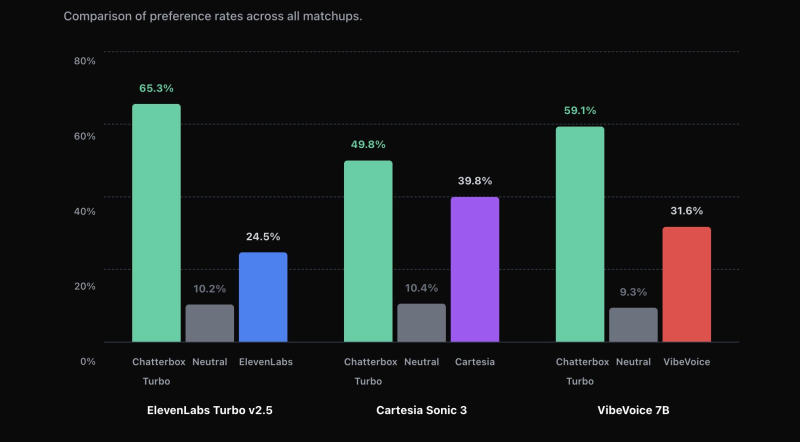
⬤ User preference tests show strong performance across competitors. Against ElevenLabs Turbo v2.5, Chatterbox-Turbo scored 65.3 percent preference versus 24.5 percent. In tests against Cartesia Sonic 3, it achieved 49.8 percent preference compared to 39.8 percent. The model also outperformed VibeVoice 7B with 59.1 percent preference versus 31.6 percent.
⬤ The launch reflects growing demand for efficient, low-latency voice AI. By enabling quality speech generation on single GPUs with local or live deployment options, Chatterbox-Turbo addresses the need for scalable real-time AI workloads. This development highlights how optimized inference is expanding voice-based applications across platforms and industries.
 Usman Salis
Usman Salis


