 Sergey Diakov
Sergey Diakov

⬤ Here's what's new: Chapter 5 introduces a structured self-refinement loop where language models literally critique and upgrade their own answers through multiple rounds. The workflow diagram shows exactly how this plays out—prompts feed into initial answers, which then get critiqued, refined, and scored in a repeatable process that happens entirely at inference time.
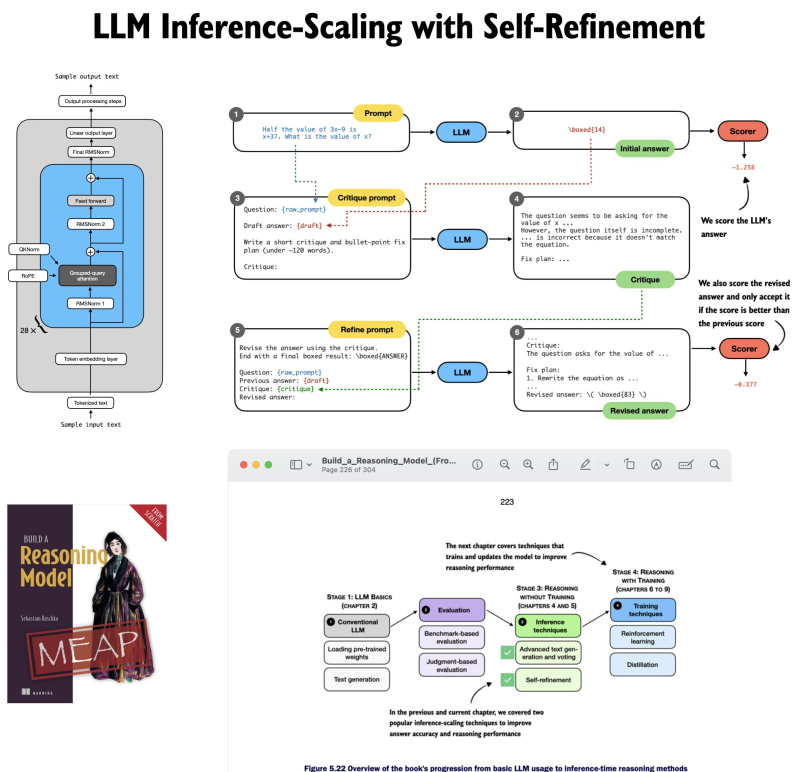
⬤ This goes further than earlier methods like self-consistency or majority voting. The refinement loop actually evaluates whether each revision beats the previous answer, using a scoring system that only keeps improvements. It's all about boosting reasoning quality during inference without touching model parameters—a core theme throughout the chapter.
⬤ Beyond the refinement loop itself, the chapter lays groundwork for upcoming reinforcement learning content by introducing log-probability scoring and structured output evaluation. Everything's implemented from scratch with working code that demonstrates how these reasoning techniques actually function. The early-access version now sits at roughly 300 pages, wrapping up its inference-time reasoning focus before diving into reinforcement learning.

⬤ Why this matters: Inference-time reasoning is becoming the go-to approach for improving model performance without extra training cycles. Self-refinement loops and scoring mechanisms can seriously level up answer quality while keeping deployment straightforward. As these methods gain traction, they'll likely reshape how reasoning-focused models get evaluated, optimized, and deployed across research labs and production systems.
 Sergey Diakov
Sergey Diakov


