 Peter Smith
Peter Smith

⬤ Parameter-efficient fine-tuning is reshaping how developers work with large language models. Five major approaches now allow teams to adapt pretrained models using smaller, low-rank matrices instead of modifying entire parameter sets. These techniques significantly reduce compute demands while keeping models flexible and powerful.
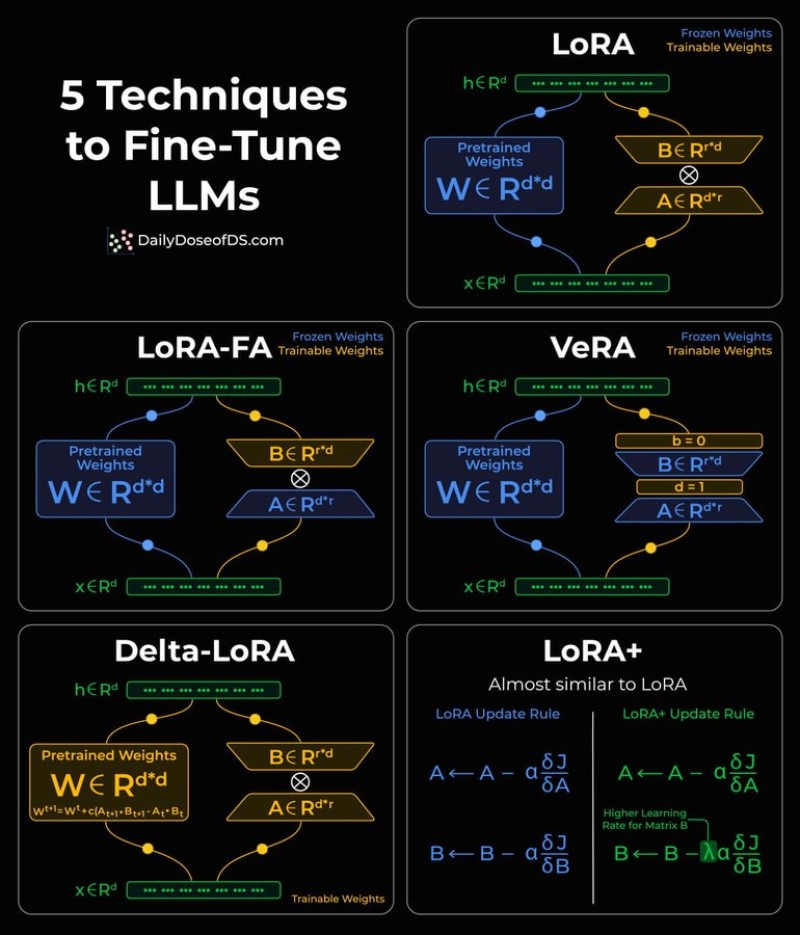
⬤ LoRA leads the pack by adding two lightweight trainable matrices alongside frozen pretrained weights. LoRA-FA takes this further by freezing one matrix to slash activation memory needs. VeRA freezes and shares low-rank matrices across all layers, training only small scaling vectors. Delta-LoRA applies changes directly back into main model weights during training. LoRA+ tweaks learning rates between matrices—"This asymmetric learning approach can significantly improve convergence speed," helping models adapt faster with fewer resources.
⬤ The payoff is dramatic: all five methods let even massive LLMs incorporate fine-tuning adjustments using just a few megabytes of extra storage. Visual breakdowns clearly show which neural network components stay frozen and which remain trainable in each variation, making the efficiency gains easy to understand compared to traditional full-scale retraining.
⬤ These advances matter because organizations need language models but struggle with compute costs and deployment complexity. Better fine-tuning techniques are changing how AI systems get adapted across industries, influencing broader adoption trends throughout the technology and semiconductor markets.
 Peter Smith
Peter Smith


