 Peter Smith
Peter Smith

The AI landscape just witnessed a significant shift as Grok-4.20 Beta 1 storms to the forefront of search-based performance metrics. With a commanding lead in Search Arena and strong showings across multiple evaluation platforms, this 500-billion-parameter model is redefining competitive benchmarks in the space.
Grok-4.20 Beta 1 Achieves #1 Search Arena Ranking With 1226 Points
Grok-4.20 Beta 1 has captured the top position in Search Arena, based on current leaderboard data. The model earned a score of 1226 ±9 (preliminary) backed by nearly 4,000 votes, demonstrating solid performance in search-grounded reasoning tasks. It also landed at #4 in Text Arena, showing versatility across different evaluation formats.
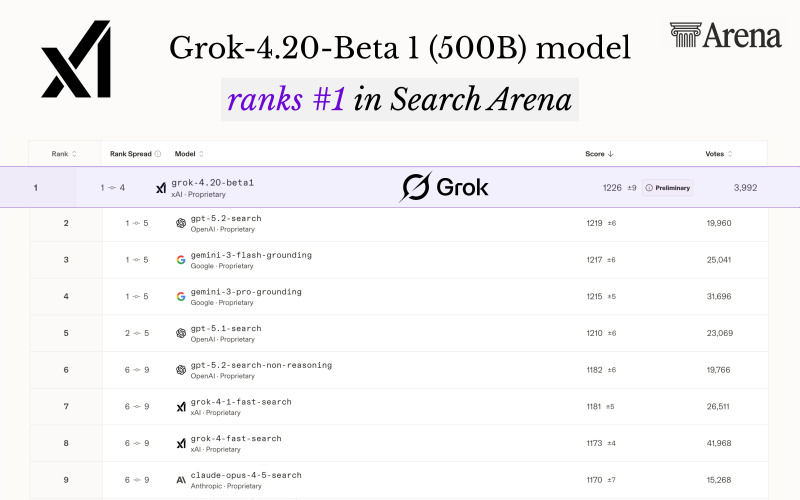
The Search Arena rankings place Grok ahead of GPT-5.2-search and multiple Gemini variants, reflecting its edge in comparative testing. Meanwhile, broader benchmark ecosystems continue showing varied leadership - GLM 4.7 recently cracked the top 68 among 369 AI models on the Artificial Analysis Index, illustrating how different models excel in different contexts.
The model operates with approximately 500 billion parameters, emphasizing efficiency relative to some larger-scale competitors.
In the detailed ranking table, GPT-5.2-search holds second place at 1219 ±6, followed by Gemini-3-flash-grounding at 1217 ±6 and Gemini-3-pro-grounding at 1215 ±5. Other notable entries include GPT-5.1-search and Claude-Opus-4-5-search. All results carry preliminary status, meaning rankings could shift as more votes roll in.
How Grok-4.20's 500B Parameters Stack Up Against Competitors
Performance in Arena settings can vary significantly across task formats. Extended evaluations sometimes favor different systems - Claude Opus 4.5 outperformed GPT-5.1 on tasks lasting eight hours, showing that longer-duration challenges can reveal different strengths. Arena scoring prioritizes outcome performance over raw model size, meaning efficiency matters as much as scale.
Grok's results have been tracked across alternative evaluation environments too. Grok-4.20 posted 1211 returns in the Alpha Arena trading competition, demonstrating capabilities beyond traditional NLP benchmarks.
Grok-4.20 Beta 1's leadership in Search Arena underscores the competitive dynamics driving AI evaluation today. As platforms like Search Arena and Text Arena continue shaping visibility and comparative analysis, leaderboard shifts remain closely watched throughout the AI ecosystem. The model's strong showing signals that parameter efficiency and specialized performance can challenge even the largest systems in targeted domains.
 Peter Smith
Peter Smith


