 Eseandre Mordi
Eseandre Mordi

⬤ Recent benchmark tests put two major language models head-to-head on long-running tasks, and the results show some clear differences in staying power. The comparison between Claude Opus 4.5 and GPT-5.1-Codex-Max tracked success rates across task lengths ranging from seconds to several days. Claude Opus 4.5 keeps its performance more consistent as tasks drag on, while GPT-5.1-Codex-Max starts losing steam faster once you get past the four-hour mark.
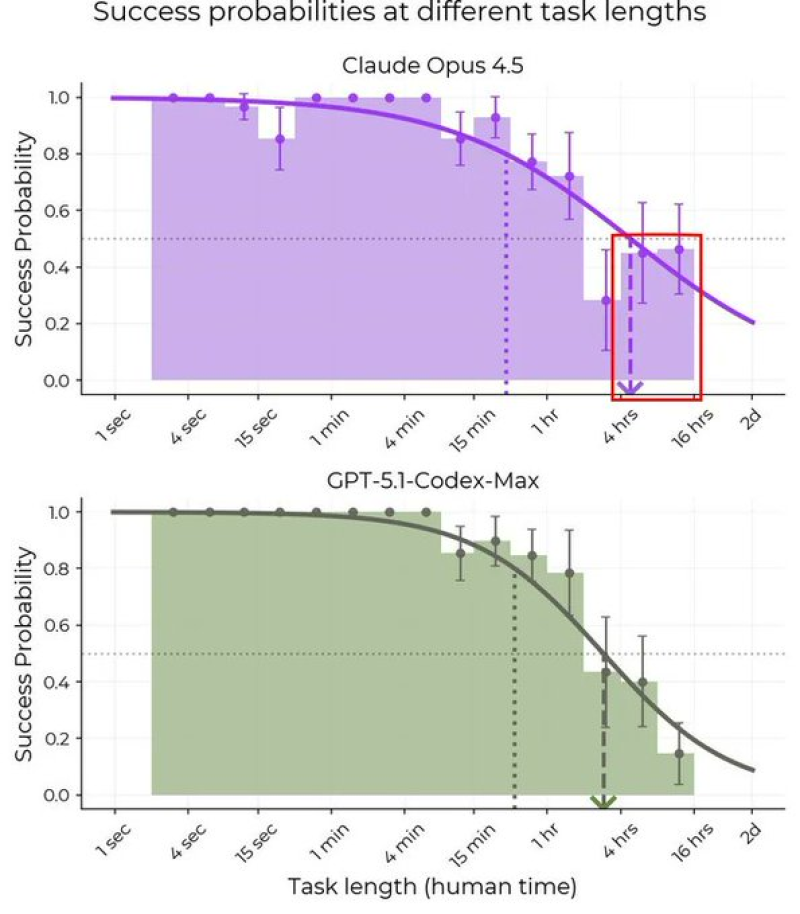
⬤ Looking at the data, Claude Opus 4.5 manages to hover around 40 percent success probability even when tasks run between eight and sixteen hours. Sure, performance drops as things get longer—that's expected—but the decline is more gradual. GPT-5.1-Codex-Max tells a different story. Once tasks push beyond one to four hours, success rates take a sharper nosedive, falling off more quickly than its competitor.
⬤ When tasks are short or medium-length, both models actually perform pretty similarly near the top of the scale. The real separation happens during those marathon sessions. The trend lines make it obvious—Opus 4.5 hangs in there longer while GPT-5.1-Codex-Max shows earlier signs of fatigue, suggesting it has a harder time maintaining consistency when workloads stretch out.

⬤ Because AI is increasingly being used for things that take hours—complex coding projects, deep research dives, extended reasoning chains, and automation workflows that don't wrap up in minutes. Models that keep higher success rates over long stretches are naturally better fits for work that needs continuous context and reliability. As benchmarks start measuring endurance alongside raw capability, data like this could shape how people choose models for agent-style tasks and long-form applications.
 Eseandre Mordi
Eseandre Mordi


