 Peter Smith
Peter Smith

⬤ A fresh benchmark visualization from METR is making waves in the AI community, showing Claude Opus 4.5 pulling ahead on long-horizon software engineering tasks. The chart tracks how long different models can work on complex problems while maintaining a 50% success rate, and Claude's newest model is clearly setting the pace.
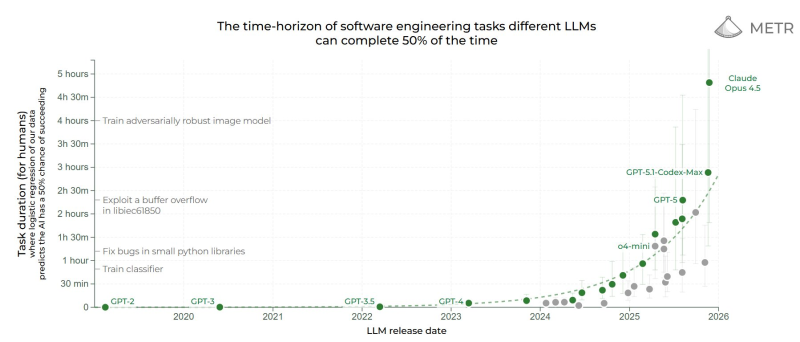
⬤ The data tells an interesting story. Claude Opus 4.5 sits at the top of the chart with task durations exceeding 4 hours, while OpenAI's recent releases—including GPT-5 and GPT-5.1 Codex-Max—cluster around the 2-3 hour mark. Earlier OpenAI models like GPT-4, GPT-3.5, and GPT-3 trail further behind, showing the progression of capabilities over time. The chart uses logistic regression calibrated against human performance, giving a realistic picture of where these systems actually stand.
⬤ The benchmark covers real-world software challenges: debugging Python libraries, training machine learning classifiers, exploiting buffer overflows, and building adversarially robust image models. What jumps out is the sharp capability jump after 2023—models are suddenly able to sustain focus and productivity over much longer time horizons. While OpenAI's models continue improving steadily, Claude Opus 4.5 appears to be pushing the boundary further in this particular dimension.

⬤ This matters because long-duration task execution is becoming the real test for AI systems. The ability to work through complex engineering problems over multiple hours without losing the thread directly translates to practical development workflows and automation scenarios. The benchmark shows competitive positioning among top models can shift rapidly as new capabilities emerge, underscoring just how fast this space is evolving.
 Peter Smith
Peter Smith


