 Saad Ullah
Saad Ullah

⬤ Claude Opus 4.5 just posted impressive gains on the WeirdML benchmark. The model jumped 21 percentage points in average accuracy while cutting its weighted cost from $27 to $9 per million tokens. For the first time, the Opus tier now clearly leads the Sonnet family in performance.
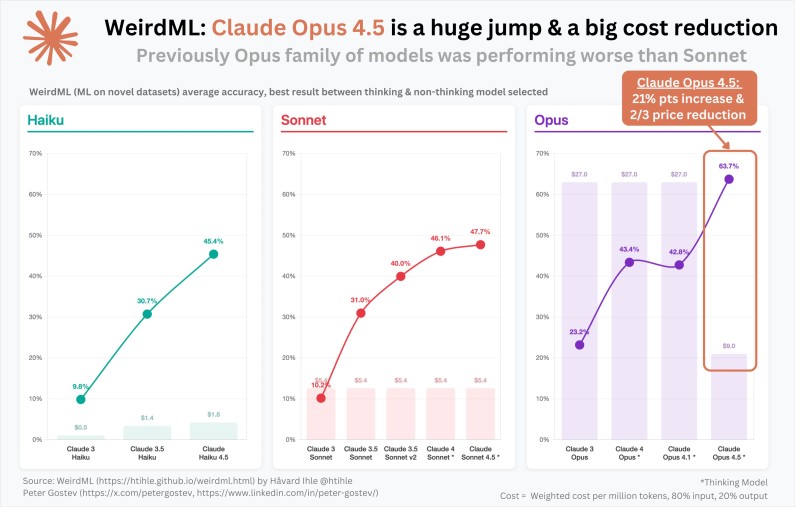
⬤ The WeirdML results show Opus 4.5 hitting 63.7% accuracy, up from roughly 42.8% in the previous version. Earlier Opus releases were competitive but never consistently beat Sonnet, which reached 47.7% in its own 4.5 update. Beyond accuracy, the price drop stands out—falling to one-third of previous levels.
⬤ While all three tiers improved, the Opus upgrade is by far the most dramatic. Haiku climbed from 30.7% to 45.4% accuracy, and Sonnet made a modest gain from 46.1% to 47.7%. The shift puts Opus at the top of Anthropic's model hierarchy, delivering stronger capabilities at a lower cost.

⬤ This advance matters for the wider AI landscape, where capability-per-dollar drives competition. A 21-point accuracy gain combined with major cost savings strengthens Anthropic's position in enterprise deployments and could reshape adoption patterns across the rapidly evolving AI market.
 Saad Ullah
Saad Ullah


