 Sergey Diakov
Sergey Diakov

⬤ GPT-5.2 Pro just crushed the FrontierMath Tier 4 benchmark with a 31% accuracy rate—way ahead of the previous 19% record. The gap isn't small. Looking at the performance chart, GPT-5.2 Pro sits clearly above everything else, and those error bars confirm the difference is real, not statistical noise.
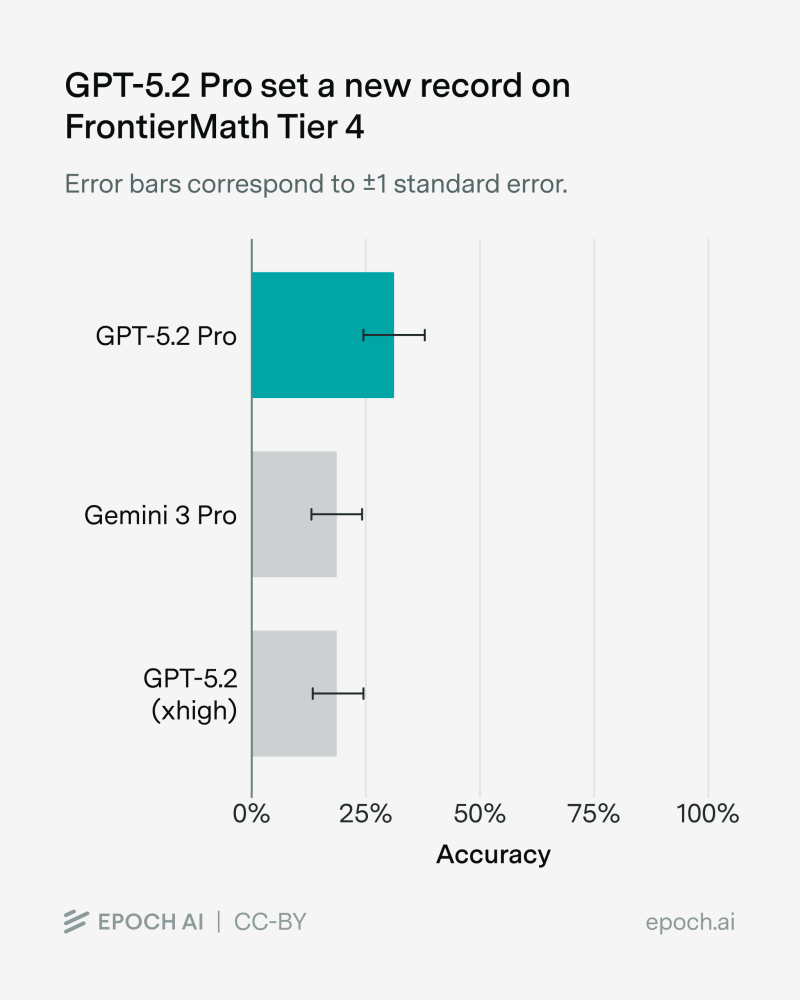
⬤ FrontierMath Tier 4 isn't your typical math test. It's built to push AI systems through multi-step reasoning and conceptual problems that go far beyond simple calculations. That 12-percentage-point leap matters because it shows consistent improvement across the board, not just lucky guesses on a few questions.
⬤ When you stack GPT-5.2 Pro against competitors like Gemini 3 Pro or even the non-Pro version of GPT-5.2, they're all stuck in the high teens. The Pro version is operating at a different level entirely. This kind of performance gap on a benchmark this tough suggests something fundamental has shifted in how these models handle complex reasoning.

⬤ Why does this matter beyond AI leaderboards? FrontierMath scores directly correlate with capabilities that scientists, engineers, and researchers actually need—advanced analytical thinking, multi-stage problem solving, technical reasoning. If models keep climbing at this rate, we're looking at AI systems that can meaningfully contribute to cutting-edge research and handle genuinely complex intellectual work.
 Sergey Diakov
Sergey Diakov


