 Eseandre Mordi
Eseandre Mordi

⬤ A new academic study introduces the Multimodal Agentic Document QA (MADQA) benchmark, built on 2,250 human-authored questions tied to 800 heterogeneous PDF documents covering complex, real-world scenarios. The research, titled "Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections," is one of the most rigorous comparisons of AI and human document reasoning to date. It arrives as the broader AI ecosystem keeps scaling up, with xAI Grok 4.20 launching with a 2M token context window and 3 model variants, pushing the boundaries of what document-level AI can realistically handle.

⬤ The top-performing system, Gemini 3 Pro, achieved roughly 82.2% accuracy, matching the human baseline. But the surface similarity masks a deeper divergence: only about 24% of correctly answered questions overlapped between humans and AI agents. Both groups consistently solved different subsets, pointing to fundamentally different reasoning and retrieval strategies. Benchmark-driven evaluations are increasingly a key competitive signal in the industry, as shown by how MedOS set a new SOTA in clinical reasoning, outperforming both GPT-5 and Gemini 3 Pro.
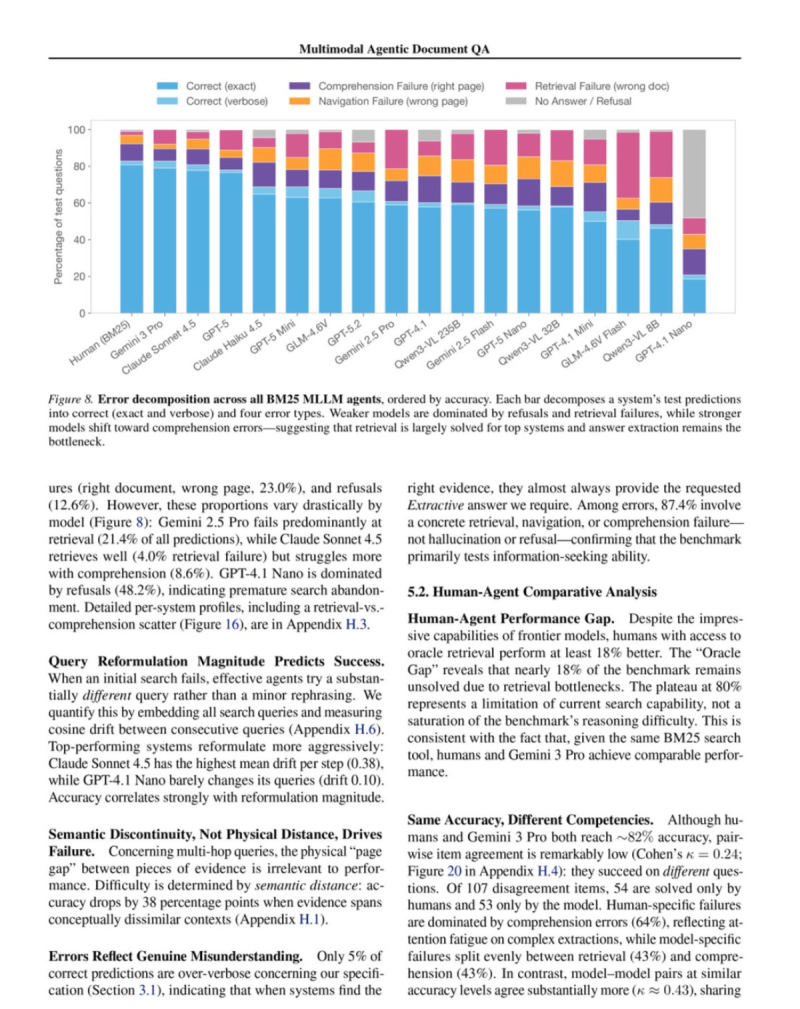
⬤ Efficiency is where humans pull clearly ahead. Human participants hit around 50% accuracy on their very first search query, while AI agents typically needed multiple retrieval rounds and query reformulations before locating relevant content. Error analysis across thousands of agent responses showed most failures were not hallucinations - they were retrieval, navigation, and comprehension errors. Research targeting agent memory is already closing this gap, as shown by how IBM's agent memory system boosted task success rates by 149%.
⬤ The clearest finding is about retrieval quality. With oracle-level document access, human accuracy jumped to roughly 99.4%, while the best AI agent stayed near 82.2%. That 17-point gap reveals that smarter navigation and retrieval strategy - not just larger models - may be the critical unlock for next-generation agentic AI. As benchmarks multiply and models evolve, understanding how AI systems actually search, retrieve, and reason across large document collections is becoming a defining question for the field.
 Eseandre Mordi
Eseandre Mordi


