 Peter Smith
Peter Smith

⬤ DeepSeek has introduced DeepSeek-Math-V2, a new open-weight mathematical reasoning system that generates and self-verifies complex proofs with impressive reliability. The model runs on the DeepSeek-V3.2-Exp framework and uses a dual-system structure pairing a theorem generator with an integrated verifier. This architecture catches and fixes errors in real time, pushing the system toward more rigorous test-time reasoning than earlier large language models.

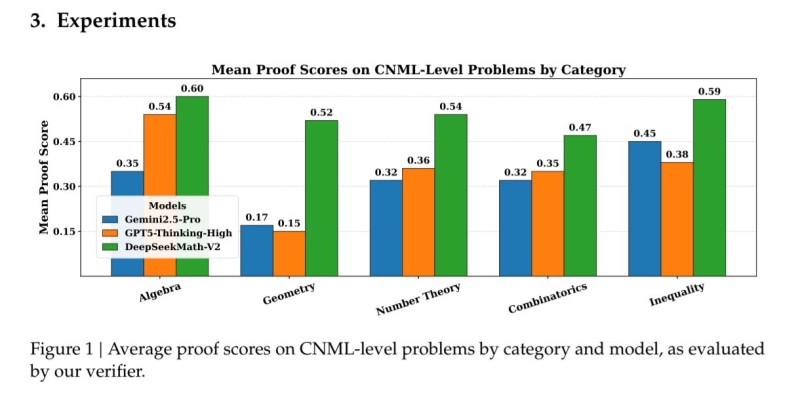
⬤ Technical benchmarks show DeepSeek-Math-V2 posting major gains across various proof categories. In CNML-level tasks, it recorded the highest mean proof scores among evaluated systems. The model hit 0.60 in algebra versus 0.54 for GPT5-Thinking-High and 0.35 for Gemini 2.5 Pro. Geometry came in at 0.52, while number theory and inequalities showed similarly strong results at 0.54 and 0.59. Expert evaluations on IMO-ProofBench further confirm its performance, with the model achieving up to 99 percent accuracy on advanced subsets and outscoring Claude, Qwen, Grok, GPT5, Gemini, and other competing models. These gains come from extensive verification loops and iterative refinement that help resolve subtle reasoning errors typically reducing accuracy in mathematical tasks.
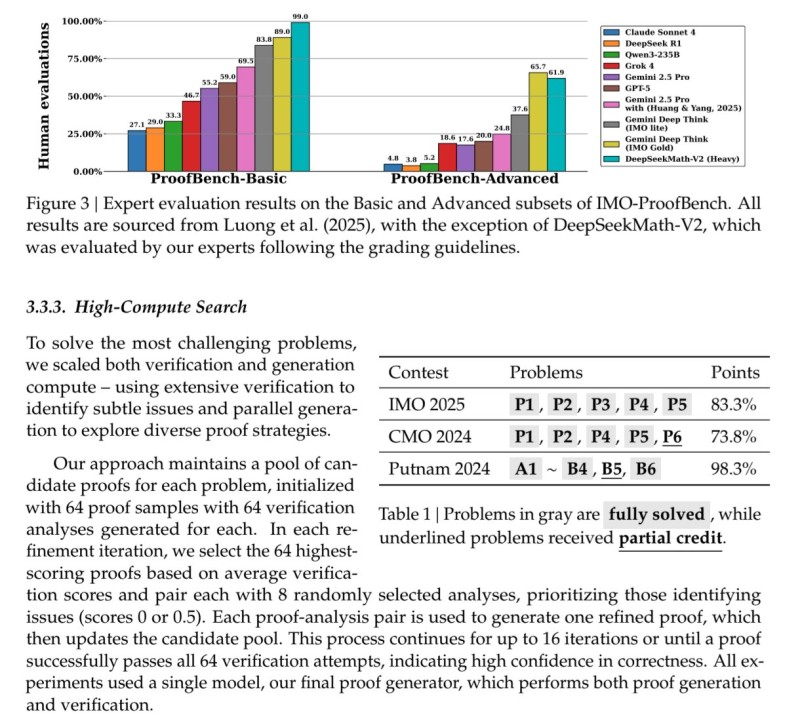
⬤ The model's performance extends to international competition benchmarks where mathematical rigor matters most. DeepSeek-Math-V2 achieved gold-level results on IMO 2025 tasks with an 83.3 percent score and reached 73.8 percent on CMO 2024. On the Putnam 2024 problem set, the system recorded one of the strongest results seen in an AI model, scoring 118 out of 120. The research describes a high-compute search procedure where candidate proofs undergo repeated verification, allowing the generator to refine solutions through up to 16 iterations until all verification attempts pass.
⬤ The release of DeepSeek-Math-V2 shows growing momentum in advanced reasoning capabilities and signals a shift toward AI systems that verify their own logic rather than rely solely on final-answer correctness. With high scores across diverse proof categories and competition problems, the model reinforces DeepSeek's position in high-level mathematical AI research and points to broader changes in how automated reasoning systems may support scientific discovery and technical problem-solving.
 Peter Smith
Peter Smith


