 Eseandre Mordi
Eseandre Mordi

⬤ The global AI race keeps heating up, with new benchmark results putting fresh pressure on established leaders. Recent testing of DeepSeek V4Lite shows the model gaining ground across several technical benchmarks. DeepSeek has been continuously updating the model served on its web interface and mobile apps, with users seeing measurable gains in the latest rounds of testing.
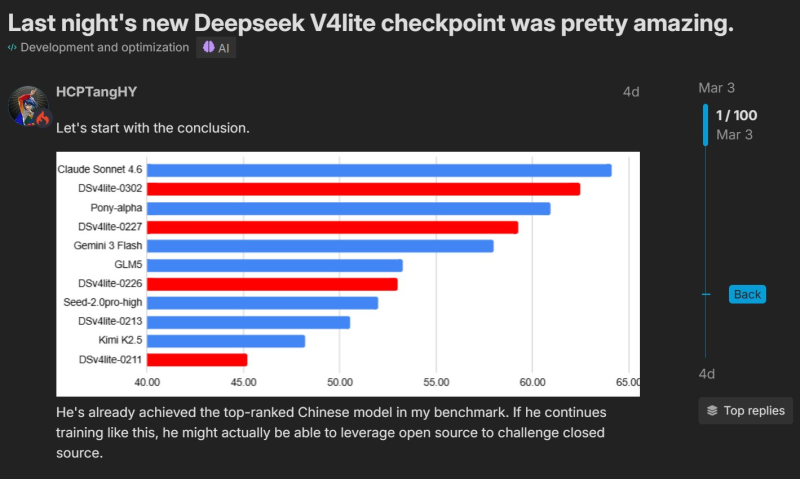
⬤ A benchmark chart circulating alongside the discussion ranks Claude Sonnet 4.6 at the top of the leaderboard, with DeepSeek V4Lite-0302 coming in second. Other models in the comparison include Pony-alpha, Gemini 3 Flash, GLM5, Seed-2.0pro-high, Kimi K2.5, and several earlier V4Lite checkpoints. The results make the latest DeepSeek checkpoint the strongest performing Chinese model in this particular benchmark.
⬤ User observations referenced in the post point to real improvements in specialized tasks. A user on a Chinese forum reported stronger results in mathematics and coding benchmarks, while others flagged gains in voxel generation, hinting at broader advances in reasoning and generation. These findings line up with the improved ranking of the V4Lite-0302 checkpoint over earlier versions like DSv4lite-0227 and DSv4lite-0213. Research has also shown that DeepSeek systems can outperform several competing models in certain tasks while remaining significantly cheaper to run than alternatives such as Claude.
⬤ The rapid iteration on DeepSeek V4Lite captures how fast the AI landscape is moving right now. Frequent checkpoint releases and benchmark gains in reasoning, coding, and generation show that the gap between leading global systems and emerging models is narrowing fast. As training techniques and hardware infrastructure improve, that pace is unlikely to slow down.
 Eseandre Mordi
Eseandre Mordi


