 Saad Ullah
Saad Ullah

⬤ NVDA-related AI discourse has picked up following a clarification about how DeepSeek V3 actually uses Multi-Token Prediction. The model, released roughly 10,000 hours ago, incorporated MTP exclusively to densify training and boost representation quality - not as an inference trick. Upcoming releases including DeepSeek GPT-5.3 and other major AI models are expected to build on these architectural decisions in new ways.

⬤ The technical formulas tied to the MTP training objective show cross-entropy loss computed across multiple token prediction positions and averaged into the training process. In plain terms, MTP helps the model extract richer features while learning - it's a representation tool, not a speed booster. As the commentary puts it directly:
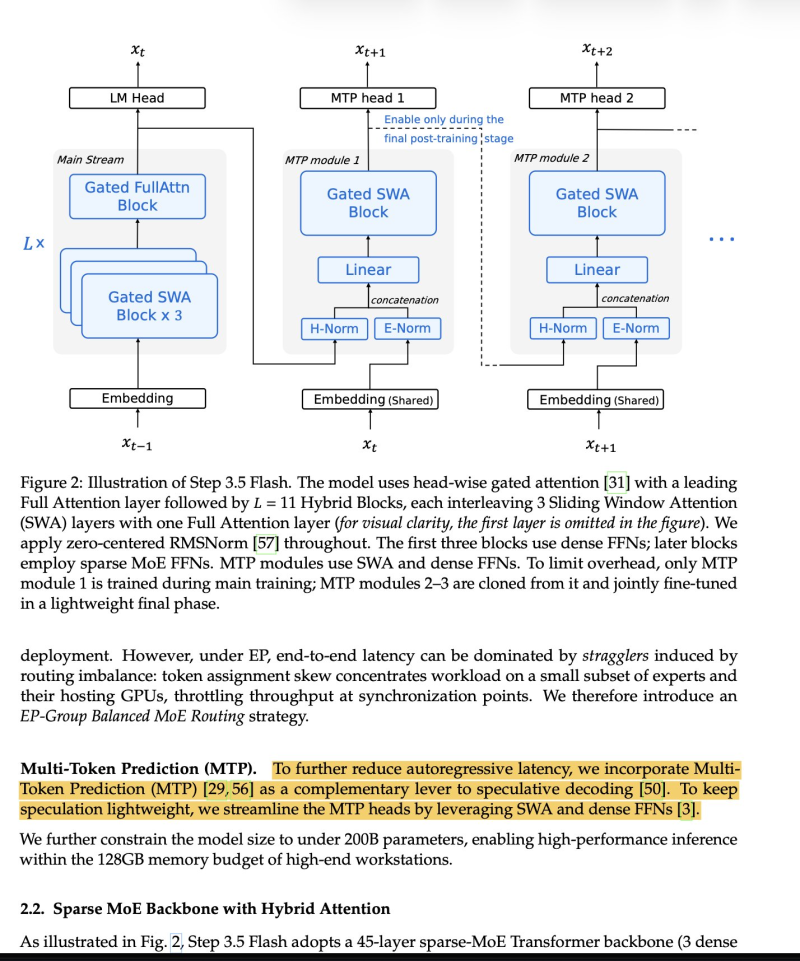
⬤ This matters more than it might seem. Optimization techniques that sharpen a model during training don't automatically carry over to faster inference at deployment. For NVDA and others in the AI ecosystem, that gap is critical - hardware utilization and inference efficiency drive real-world costs and scalability. Newer models like Step 3.5 have emerged pursuing entirely different optimization paths. DeepSeek's latest DeepSeekOCR 2 release reflects this ongoing push into more specialized, deployment-ready capabilities.
⬤ As AI development accelerates, understanding what a technique actually does - and where it stops - becomes essential for reading performance claims and architectural trade-offs honestly. MTP improved how DeepSeek V3 learns. It didn't change how fast it runs. Keeping that line clear is one of the more underrated challenges in the current AI landscape.
 Saad Ullah
Saad Ullah


