 Peter Smith
Peter Smith

⬤ Google (GOOGL) rolled out TimesFM 2.5, a decoder-only foundation model built specifically for time series forecasting, now live on Hugging Face in Transformers format. What makes this release notable is its zero-shot performance - the model can tackle forecasting tasks without needing to be fine-tuned for each specific use case. It's another example of how transformer architectures are moving beyond language and images into numerical prediction territory.
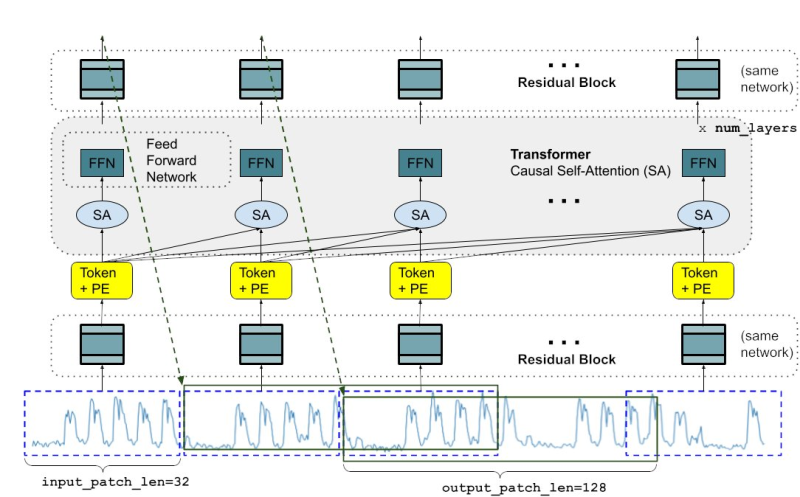
⬤ The model's architecture follows a transformer-based decoder design with causal self-attention and feed-forward network layers wrapped in residual blocks. Input sequences get divided into patches with positional encoding - the specs show input_patch_len=32 and output_patch_len=128, which lets the model handle long-range forecasting efficiently. Google took the transformer backbone that powers language models and adapted it for time-dependent data, enabling it to capture long-range patterns and predict extended horizons.
⬤ This launch fits into a broader wave of AI specialization happening across the industry. Competitive dynamics are intensifying as OpenAI extends lead as frontier AI model intelligence rises in 2025, showing how foundation models continue advancing across different domains. Large models are being tailored for niche applications beyond text generation.
⬤ TimesFM 2.5 signals where foundation models are heading next - into structured data environments where forecasting matters. By making it available on Hugging Face in Transformers format, Google opened the door for developers working in finance, supply chain optimization, energy demand modeling, and other time-series-heavy fields. Infrastructure advances like Google's control of 4-layer AI stack creates cost edge complement these modeling capabilities, while domain-specific innovations such as NVIDIA-backed VimoGen transforms AI human motion generation demonstrate the expanding scope of specialized AI applications. The model shows how transformer architectures originally designed for language are proving flexible enough to handle numerical sequences where context and long-term dependencies drive accurate predictions.
 Peter Smith
Peter Smith


