 Eseandre Mordi
Eseandre Mordi

⬤ ViMoGen introduces a sophisticated approach to human motion generation through AI. Developed by researchers from NTU, SenseTime, Tsinghua University, CUHK, and NVIDIA, the model bridges the gap between video generation and motion synthesis. The system taps into advanced video generation capabilities and repurposes them for creating realistic human movement from text descriptions or existing motion data.
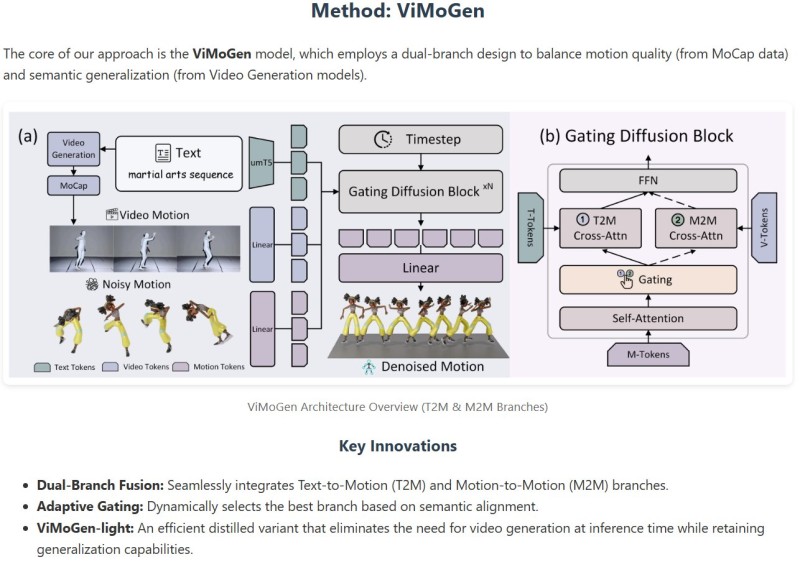
⬤ The model operates through a dual-branch design that merges Text-to-Motion and Motion-to-Motion pathways within a diffusion framework. Text tokens, video tokens, and motion tokens flow through gated diffusion blocks that intelligently balance semantic understanding with physical realism. This adaptive gating lets the system cherry-pick the most relevant information sources during generation, keeping movements natural while staying true to text prompts.
⬤ Built on a newly assembled large-scale dataset, ViMoGen outperforms existing motion generation methods across the board—delivering better motion quality, tighter prompt accuracy, and stronger adaptation to new scenarios. The team also created ViMoGen-light, a streamlined version that skips video generation during inference while maintaining robust generalization capabilities.

⬤ This breakthrough shows how video generation advances can boost motion modeling and embodied AI. By connecting video diffusion with motion generation, ViMoGen proves that cross-domain learning can create more flexible and scalable AI systems. The technology could reshape robotics, animation, virtual avatars, and simulation environments—all areas where generating realistic, controllable human motion remains a tough technical hurdle.
 Eseandre Mordi
Eseandre Mordi


