 Peter Smith
Peter Smith

Teaching AI to truly reason rather than just game the system has been a persistent challenge in machine learning. Now, researchers have developed a smarter approach that could change how we train large language models to solve complex problems.
New Framework Tackles AI's "Reward Hacking" Problem
Researchers from Hong Kong Baptist University and Shanghai Jiao Tong University created a training framework called Co-rewarding that helps large language models develop genuine reasoning skills. Published as a conference paper at ICLR 2026, the method addresses a critical flaw known as "reward hacking" - when AI systems learn to exploit scoring mechanisms instead of actually improving their thinking abilities.
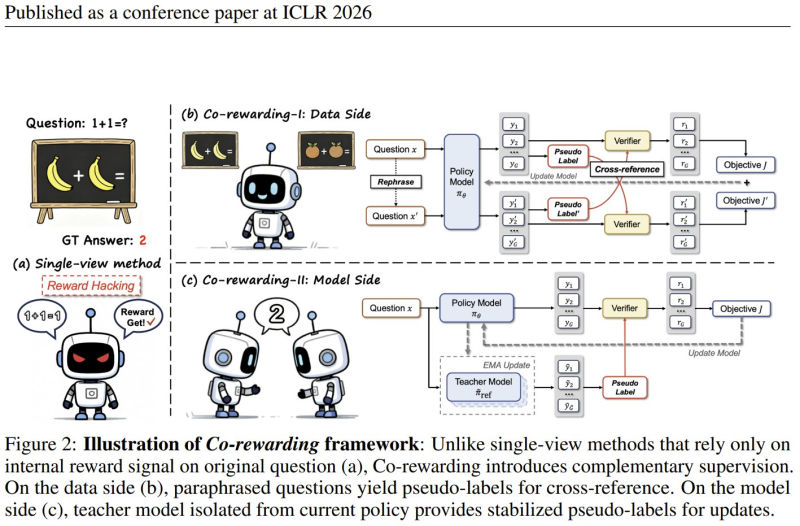
The framework works differently from traditional methods that depend only on internal reward signals. Instead, it stabilizes training by incorporating dual perspectives, which keeps the learning process on track. This approach fits into broader AI advances, including breakthrough systems like AI System Screens 10 Trillion Drug/Protein Combinations in 24 Hours that demonstrate how AI continues pushing boundaries across multiple fields.
How Co-Rewarding Works: Double-Checking AI Answers
Co-rewarding introduces two complementary mechanisms that work together. On the data side, the system creates paraphrased versions of questions to generate pseudo-labels that cross-check answers. On the model side, a separate teacher model - kept isolated from the current learning model - provides stable guidance to reduce volatility during training.
The results speak for themselves. The method beats other self-rewarding approaches by 3.31% on math reasoning benchmarks and even surpasses models trained with human-verified labels on tasks like GSM8K. Described as "Stable Self-supervised RL for Eliciting Reasoning in Large Language Models," the approach emphasizes cross-referencing answers across similar prompts while maintaining consistency through the teacher model. Similar innovations in AI training efficiency appear in developments like Adobe Reveals SelfE: New AI Method Generates Quality Images in Any Number of Steps.
What This Means for AI Development
Progress in self-supervised reinforcement learning frameworks could support more stable and scalable training approaches for reasoning-focused AI systems. Reducing reliance on human-verified labels while maintaining competitive performance might accelerate development of robust language models across research and commercial applications, making advanced AI more accessible and reliable.
 Peter Smith
Peter Smith


