 Victoria Bazir
Victoria Bazir

⬤ Vision Wormhole is a freshly surfaced AI framework that flips the script on how large models talk to each other. Instead of passing text back and forth - slow, token-capped, and lossy - it proposes using vision systems as a universal communication port. Models convert their internal reasoning into compact visual representations, share them as images, and let the receiver's vision encoder do the unpacking. It's a genuinely different take on model-to-model messaging.
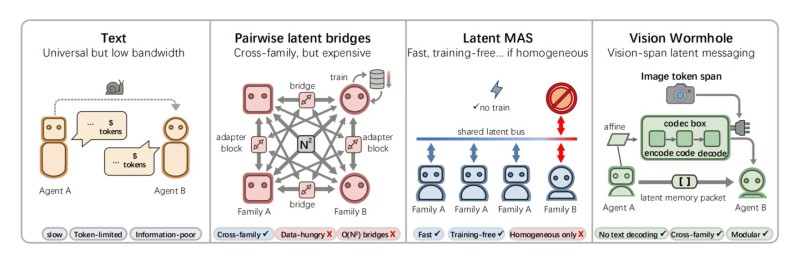
⬤ The framework maps out four approaches to inter-model communication, and Vision Wormhole is the only one that checks all the boxes. Standard text messaging is universal but painfully low-bandwidth. Pairwise latent bridges are fast but data-hungry and don't scale across model families. Latent multi-agent systems work well in homogeneous setups but fall apart when mixing different architectures. Vision Wormhole sidesteps all of this with image token spans and a codec box that encodes, transmits, and decodes latent memory packets across families - no explicit text decoding required.
⬤ Mechanically, the sender model encodes its reasoning into a special visual format and fires it off as an "image." The receiver processes it straight through its vision encoder - no bottleneck, no translation loss. It's modular, cross-family compatible, and keeps internal representations intact in a way that text simply can't. Research into vision language action models shaping embodied AI research shows just how fast visual reasoning is moving up the priority list across the field.
⬤ Vision Wormhole lands at a moment when the broader AI ecosystem is pushing hard on efficiency and autonomy. An AI system that generated $10,000 in 7 hours through real work tasks and innovations like the nanobot cutting agent code by 99% point to the same underlying drive - doing more with less overhead. Vision Wormhole's visual latent channel fits right into that picture, and could shape how AI systems interoperate at scale going forward.
 Victoria Bazir
Victoria Bazir


