 Usman Salis
Usman Salis

⬤ Z.ai has officially rolled out GLM-4.7-Flash, a 30B-parameter language model that balances solid performance with efficiency for local and lightweight deployments. The model handles a wide range of tasks, from coding and long-context reasoning to translation, creative writing, and roleplay. Free model weights are now available on Hugging Face, and the company offers both a free API tier and a faster paid version called GLM-4.7-FlashX.
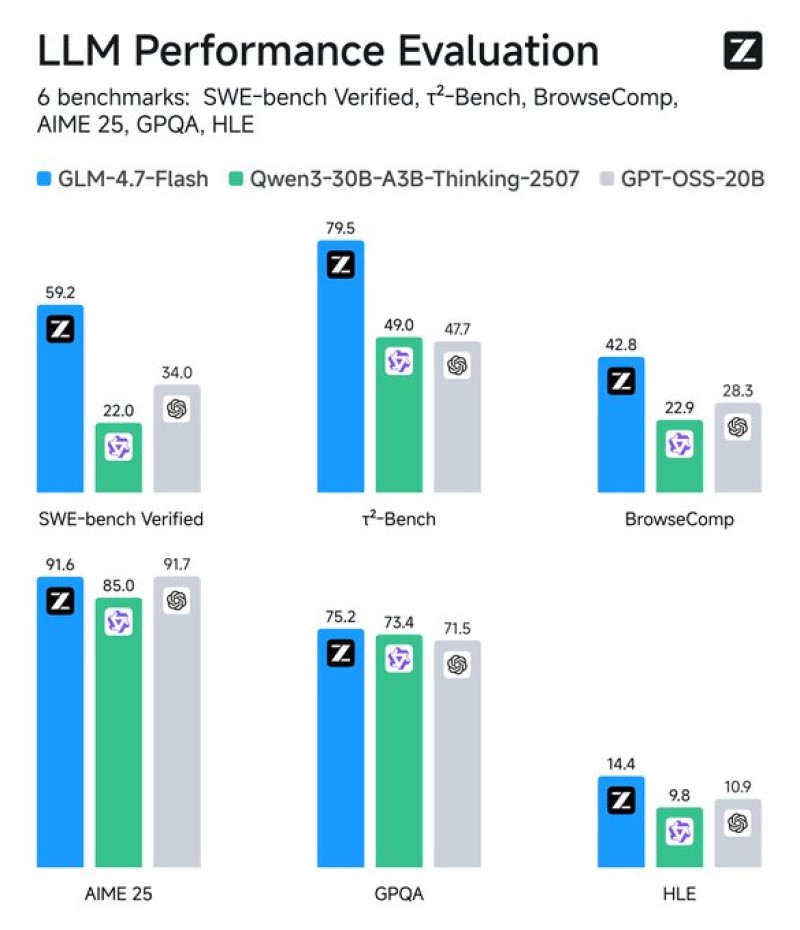
⬤ GLM-4.7-Flash scored 59.2 on SWE-bench Verified, outperforming both Qwen3-30B-A3B-Thinking-2507 and GPT-OSS-20B in head-to-head comparisons. On τ²-Bench, it hit 79.5, leading the peer group shown in the benchmark chart. These results point to strong capabilities in software engineering and structured reasoning compared to similarly sized models.
GLM-4.7-Flash targets a broad range of use cases while remaining efficient enough for local deployment.
⬤ The model delivered consistent results across knowledge and reasoning tests. It scored 42.8 on BrowseComp, 91.6 on AIME 25, and 75.2 on GPQA, placing at or near the top in each category. On the HLE benchmark, which tests complex reasoning under tight conditions, GLM-4.7-Flash reached 14.4—modest overall but still ahead of competing models in the comparison set.
⬤ The launch of GLM-4.7-Flash highlights a shift toward performance-efficient models rather than just bigger parameter counts. By combining competitive benchmark scores with open-access weights and flexible API pricing, Z.ai is offering a practical option for developers who want capable models without the heavy infrastructure costs. The benchmark data shows that efficiency-focused models are closing the gap with larger systems across real-world tasks.
 Usman Salis
Usman Salis


