 Peter Smith
Peter Smith

⬤ Tencent's rolling out something interesting with its AngelSlim framework. The company's targeting one of AI's biggest cost headaches: inference time. Their Hunyuan AI team built a new architecture called Eagle3 that's rethinking how large models actually generate outputs. Instead of the usual token-by-token grind, they're using a smarter draft-and-verify system that's showing real-world speedups between 1.4x and 1.9x.
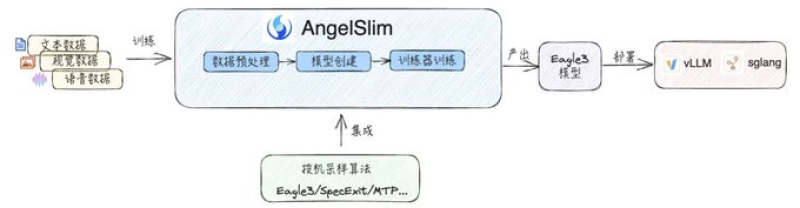
⬤ Here's how it works. A smaller draft model runs ahead of the main model—whether that's an LLM or vision language model—and predicts what's coming next. The larger model then verifies those predictions in parallel rather than sequentially. It's cutting down on wasted computation and boosting throughput without the usual quality trade-offs you'd expect from speed optimizations.
Eagle3 extends speculative sampling from a narrow optimization technique into a general-purpose acceleration method applicable across different model types.
⬤ What makes this upgrade worth paying attention to is that it's working across the board. Text generation, vision tasks, speech models—they're all seeing gains, and Tencent claims there's virtually no quality loss. That's the part that matters most, because plenty of inference tricks can make things faster by cutting corners. This one apparently doesn't.

⬤ Why does this matter? Because inference costs are what make or break AI deployments at scale. Faster inference means lower compute bills, snappier response times, and the ability to actually deploy these massive multimodal models without burning through resources. If a small draft model can reliably accelerate bigger models without trashing output quality, that's a practical path forward—especially as AI applications keep getting more complex and expensive to run.
 Peter Smith
Peter Smith


