 Peter Smith
Peter Smith

A new research breakthrough in AI video generation, StreamDiffusionV2, has been introduced by researchers from UT Austin, UC Berkeley, Stanford, MIT, and other institutions. As JIQIZHIXIN reported, the system enables real-time, interactive video generation for live streaming scenarios. The pipeline uses scheduling and parallel processing techniques to optimize diffusion models for continuous output, marking a step forward in real-time generative AI alongside broader system-level innovations like TrustSQL, which recently signaled a major shift in AI data systems.
StreamDiffusionV2 enables real-time, interactive video generation for live streaming scenarios, combining low latency with scalable performance.
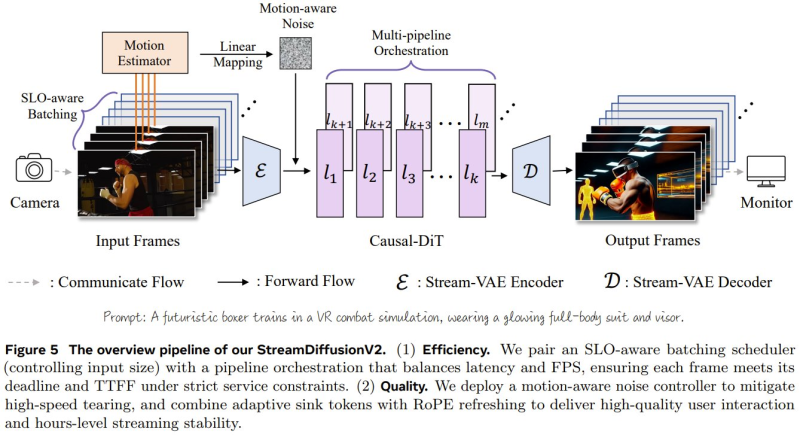
StreamDiffusionV2 is designed as a training-free pipeline that incorporates SLO-aware batching, motion-aware noise control, and multi-pipeline orchestration.
These components allow the system to balance latency and visual quality while processing streaming input frames. The architecture parallelizes diffusion steps across multiple stages, improving efficiency and enabling stable, continuous generation. According to research details, the system achieves near-linear scaling across GPUs while maintaining strict latency constraints.
StreamDiffusionV2 Performance: Sub-0.5s Latency and 64 FPS on 4 H100 GPUs
Performance benchmarks highlight the system's capabilities, delivering the first generated frame in under 0.5 seconds and achieving up to 64 frames per second on four H100 GPUs. This represents a substantial improvement over prior diffusion-based approaches, which often struggled to meet real-time requirements. The ability to sustain both speed and quality aligns with growing demand for interactive AI systems, as reflected in a Stanford study showing AI models agree with users 50% more than humans do.
The system achieves near-linear scaling across GPUs while maintaining strict latency constraints, delivering the first generated frame in under 0.5 seconds.
StreamDiffusionV2 Marks a Shift in Real-Time AI Video Applications
The development highlights a broader shift toward real-time, interactive AI systems capable of continuous operation. By combining low latency with scalable performance, StreamDiffusionV2 demonstrates how diffusion-based models are evolving beyond offline generation into live applications. This progression signals increasing momentum in areas such as live streaming, virtual environments, and real-time content creation, where responsiveness and stability are critical for widespread adoption - a trend further reflected in advancements like Grok Imagine Video hitting #1 on the image-to-video leaderboard.
StreamDiffusionV2 demonstrates how diffusion-based models are evolving beyond offline generation into live applications.
 Peter Smith
Peter Smith


