 Eseandre Mordi
Eseandre Mordi

⬤ Researchers from Meituan and the University of Chinese Academy of Sciences have introduced TRUST-SQL, a Text-to-SQL framework that removes the need for pre-loaded database schemas. The system runs a four-phase workflow where an AI agent explores schema information, proposes relevant structures, generates SQL queries, and confirms the final answer through validation steps similar to those seen in Stanford's synthetic data efficiency research.
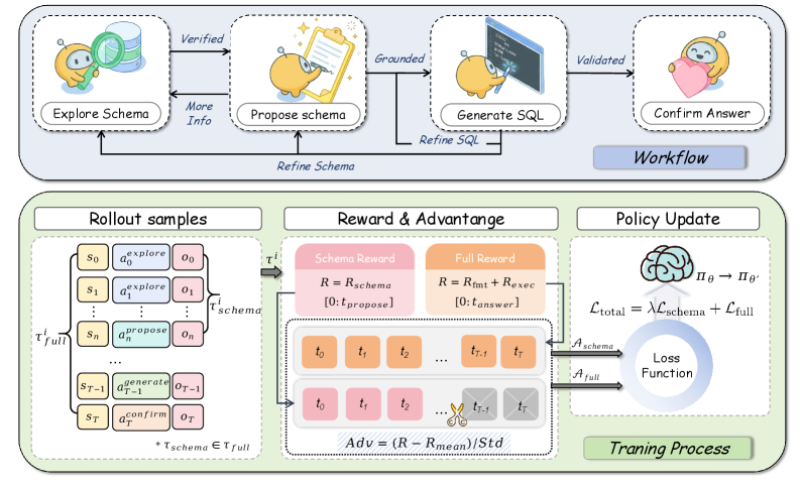
⬤ Unlike traditional systems that rely on static metadata, TRUST-SQL uses a dynamic interaction model. Instead of receiving a full schema upfront, the agent identifies and verifies only the relevant subset of database information at runtime. The workflow follows four key stages: Explore, Propose, Generate SQL, and Confirm Answer, with iterative refinement loops that improve both schema understanding and query accuracy over time.
⬤ TRUST-SQL runs on a Dual-Track GRPO training method that separates schema-related rewards from final query execution outcomes. This makes reinforcement learning more precise and improves credit assignment across different stages of the task. Results show a 9.9% performance improvement over standard RL approaches while matching systems that rely on full schema access - a result that parallels the scaling pressures now shaping AI infrastructure investment.
⬤ The development highlights a broader shift toward flexible, adaptive data interaction models. By eliminating dependency on pre-loaded schemas, TRUST-SQL shows how AI agents can operate across environments where database structures are large, dynamic, or partially unknown - expanding practical use cases for Text-to-SQL across enterprise systems where AI infrastructure growth and scaling challenges continue to intensify.
 Eseandre Mordi
Eseandre Mordi


