 Peter Smith
Peter Smith

A new framework for Transformer efficiency is getting attention from the AI research community. Developed by researchers at Carnegie Mellon University and Meta, STEM replaces the standard feed-forward up-projection layer with a token-indexed embedding lookup system, offering a fresh take on how large language models handle per-token computation. The result is a leaner architecture that cuts parameters and reduces floating-point operations without sacrificing accuracy.
How STEM Replaces Traditional Feed-Forward Layers
Standard Transformer feed-forward networks, including SwiGLU and Mixture-of-Experts (MoE) designs, compute dynamic transformations for every token at every layer. STEM takes a different route: instead of computing, it retrieves.
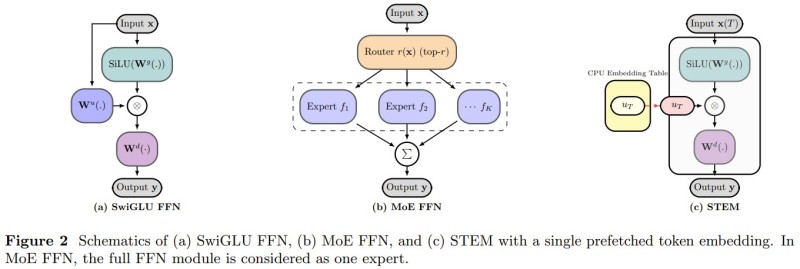
Each token pulls its representation directly from a static embedding table, turning the computation into a structured memory lookup. This eliminates redundant calculations and reduces communication overhead across model layers, while also cutting feed-forward network parameters by roughly one-third. The shift is conceptually similar to what made TrustSQL's 99% accuracy gains possible: smarter data access patterns beating brute-force computation.
3-4% Accuracy Gains on MMLU and Stronger Long-Context Stability
The efficiency gains come with measurable performance uplifts. Across reasoning and knowledge benchmarks, STEM delivers 3-4% accuracy improvements on tasks like MMLU. The architecture also handles long-context scenarios better than standard Transformers and shows improved overall stability, two areas where traditional scaling approaches tend to run into trouble. These results fit into a broader wave of compact, capable models rewriting assumptions about what smaller architectures can do - seen also in Essential AI's 8B RNJ1 model competing head-to-head with much larger systems, and in retrieval-aware design approaches like AutoGeo's 2-model framework.
STEM points to a practical direction for scaling under compute constraints: structured memory over dynamic computation. As model size and deployment costs continue to climb, architectures that balance accuracy with efficiency could play a defining role in what gets built next.
 Peter Smith
Peter Smith


