 Peter Smith
Peter Smith

⬤ Researchers from Toyota Research Institute and Tsinghua University have published a large-scale study on how robots can learn complex tasks more efficiently using Large Behavior Models. The work centers on co-training strategies that blend multiple data modalities, showing robots can generalize to new tasks without relying on expensive task-specific data collection.
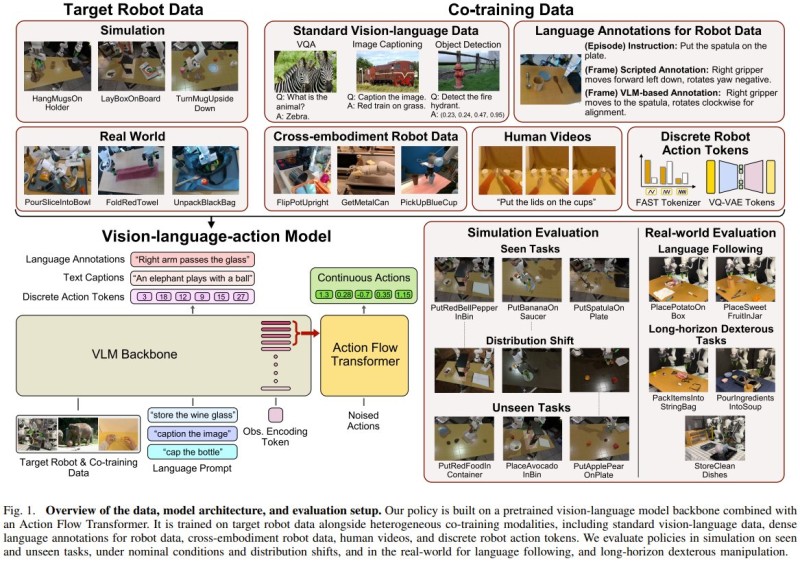
⬤ The framework pulls together simulation data, real-world demonstrations, human videos, and vision-language datasets into a single training pipeline. It taps over 4,000 hours of robot and human data alongside millions of vision-language samples. The architecture pairs a pretrained backbone with an action transformer, letting robots translate natural-language instructions into both continuous and discrete physical actions.
⬤ Combining vision-language data with cross-embodiment robot data measurably improves performance on unseen tasks, distribution shifts, and language-following scenarios. Prior work on Large Behavior Models confirms that scaling diverse training cuts required data by several times while boosting robustness. Evaluations cover both simulation and real-world environments, including long-horizon dexterous manipulation where Ant Group's LingBot VLA universal robot control model trained on 20,000 hours demonstrates similar scaling gains.
⬤ These results reflect a broader shift toward scalable, general-purpose robotics. Real-world deployment is already accelerating, with Toyota Canada bringing Agility Robotics' Digit into factory operations as a live example. The convergence of AI reasoning and physical action is also visible in how AI systems are learning to act rather than just predict - a shift that positions Large Behavior Models at the center of next-generation robotics.
 Peter Smith
Peter Smith


