 Usman Salis
Usman Salis

⬤ A team from Hong Kong University of Science and Technology just released One4D, an AI model that creates complete 3D video environments from surprisingly little input. Feed it one image, a handful of video frames, or full footage, and it generates consistent 4D scenes—meaning 3D space that moves through time.
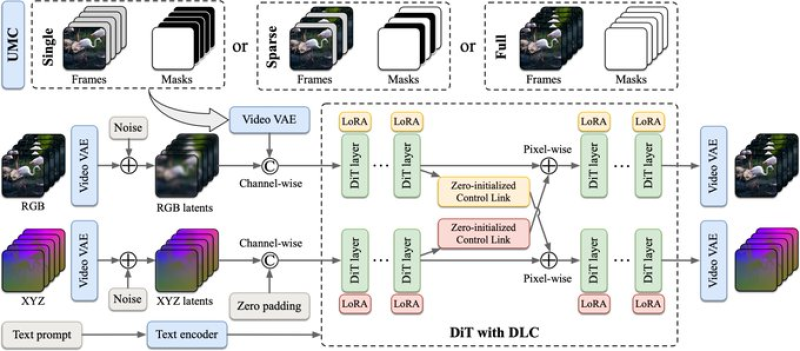
⬤ What makes One4D different is its Decoupled LoRA Control approach. Instead of trying to handle colors and 3D shapes together (which usually means sacrificing one for the other), it processes them separately first, then syncs them up. This lets the system produce videos where objects look good and actually move like they should, without the geometry falling apart or the motion getting weird.
⬤ The model combines video variational autoencoders with transformer-based diffusion technology. LoRA modules work at different points in the pipeline, using zero-initialized controls to keep the visual appearance locked in with the underlying 3D structure. This setup works across multiple scenarios—whether you're starting with a single photo, sparse frames, or complete video—and consistently outperforms earlier 4D generation methods.

⬤ One4D matters because it shows where generative AI is headed beyond flat images and short clips. When models can reliably build coherent 3D video worlds from minimal starting material, that opens doors for VR experiences, digital content production, realistic simulations, and interactive media. As AI gets better at understanding both space and time together, techniques like Decoupled LoRA Control could become standard tools for the next wave of video and 3D generation.
 Usman Salis
Usman Salis


