 Eseandre Mordi
Eseandre Mordi

A team of researchers from Shanghai Jiao Tong University and Xiaohongshu has introduced JTok, a scaling method that expands large language model capacity along a new axis: token embeddings. Instead of scaling up model size or compute proportionally, JTok lets models grow smarter without growing much heavier.
How JTok Modulates the Transformer Without Breaking the Bank
The core idea is elegant. Standard Transformer layers are augmented with token-indexed parameters stored in auxiliary embedding tables. Each token pulls a vector tied to its token ID, normalizes it, and applies it as a multiplicative gate over the feed-forward network update.
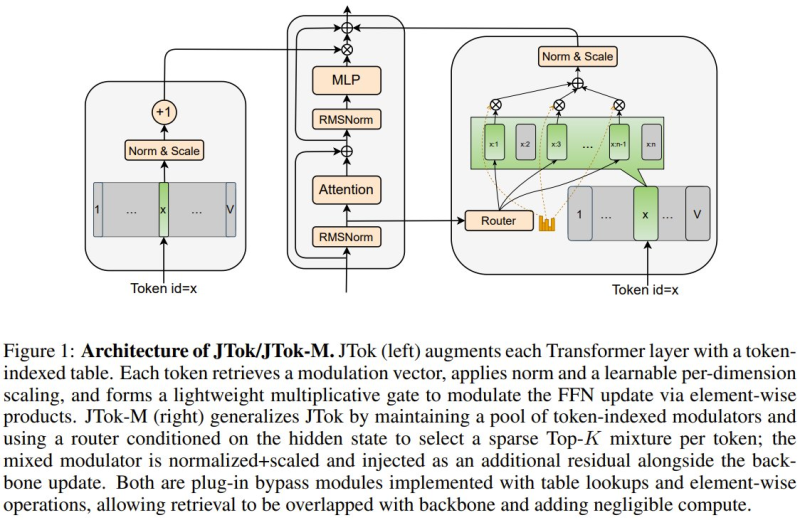
The result is a lightweight modulation layer that adds expressive power with almost no computational overhead. Similar efficiency-driven thinking has shaped recent work like Alibaba's Qwen 3.5 Small Models, where compact architectures matched larger models on reasoning benchmarks.
"The technique decouples model capacity from compute cost, one of the more practical directions in LLM scaling today."
JTok-M Pushes Further With Sparse Mixture of Modulators
The framework extends into JTok-M, a variant that maintains a pool of token-indexed modulators. A router conditioned on each token's hidden state selects a sparse Top-K mixture from that pool, blending chosen modulators before injecting the result as an additional residual alongside the standard Transformer update. Capacity scales up, FLOPs stay controlled. It's a design philosophy proving influential beyond this paper, as seen in work like MedOS and its new SOTA on clinical reasoning, where novel architectures continue to push performance ceilings across domains.
Benchmark results back up the efficiency claims. JTok delivers gains of +4.1 on MMLU, +8.3 on ARC, and +8.9 on CEval, all while achieving comparable quality at roughly 35% less compute than vanilla Mixture-of-Experts models. For teams looking to scale without proportional infrastructure costs, JTok offers a compelling trade-off worth watching.
 Eseandre Mordi
Eseandre Mordi


