 Eseandre Mordi
Eseandre Mordi

⬤ A new automated translation benchmarking framework is turning heads in AI research circles. Dubbed "Recovered in Translation," the approach applies test-time compute scaling to generate multiple candidate translations from a base LLM, then ranks them using USI and T-RANK metrics. The results are striking: according to recent coverage of AI reasoning frameworks pushing beyond standard benchmarks, LLM judge models preferred the highest-ranked outputs at a 4:1 ratio compared to existing translation resources, a meaningful leap over conventional approaches.
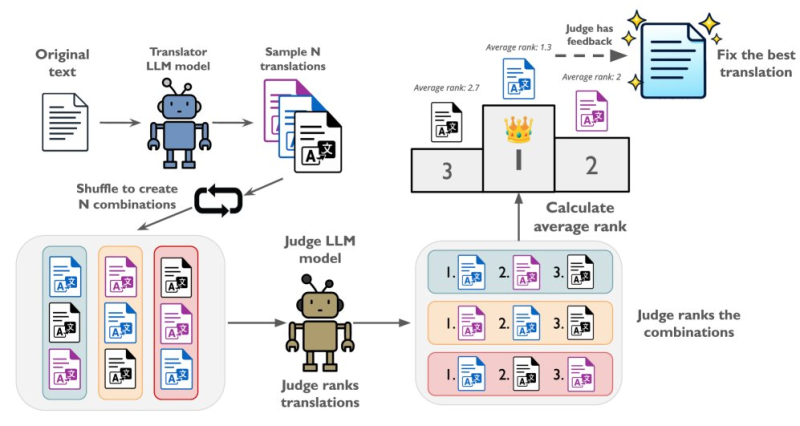
⬤ The mechanics are straightforward but clever. A translator model generates several candidate translations from the same source text. Those candidates are then shuffled into combinations and handed off to a separate judge LLM, which ranks each combination and calculates average scores per candidate. The top-ranked output becomes the final translation. No retraining required, no human-in-the-loop at inference time, just smarter use of compute at the output stage.
Performance at inference time is increasingly leveraged without retraining base models, a shift with real implications for how AI systems are evaluated and deployed.
⬤ This kind of inference-time optimization is becoming a recurring theme across AI research. Rather than building bigger models, teams are squeezing more quality out of existing ones through ensemble ranking, sampling diversity, and structured evaluation loops. Similar gains have appeared elsewhere: MedixR1 recently hit 73.6% accuracy in medical diagnosis using comparable framework-level innovations, and a separate reasoning approach boosted AI performance by 331% without any human verification.
⬤ For the translation space specifically, the implications are practical. Higher quality benchmarks, more reliable multilingual output, and reduced dependence on static training data all matter for real-world deployment. As structured ranking mechanisms mature, they are likely to reshape expectations for what production-grade AI translation should actually look like, and raise the bar for everyone competing in that space.
 Eseandre Mordi
Eseandre Mordi


