 Eseandre Mordi
Eseandre Mordi

⬤ A new study from MIT CSAIL titled Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights is shaking up assumptions about how LLMs actually learn to reason. Authored by Yulu Gan and Phillip Isola, the paper suggests that core reasoning abilities may emerge through structured synthetic training rather than from exposure to human-written text alone. The research maps out how pretrained models organize knowledge inside their weight space - and what that means for how we build AI going forward.
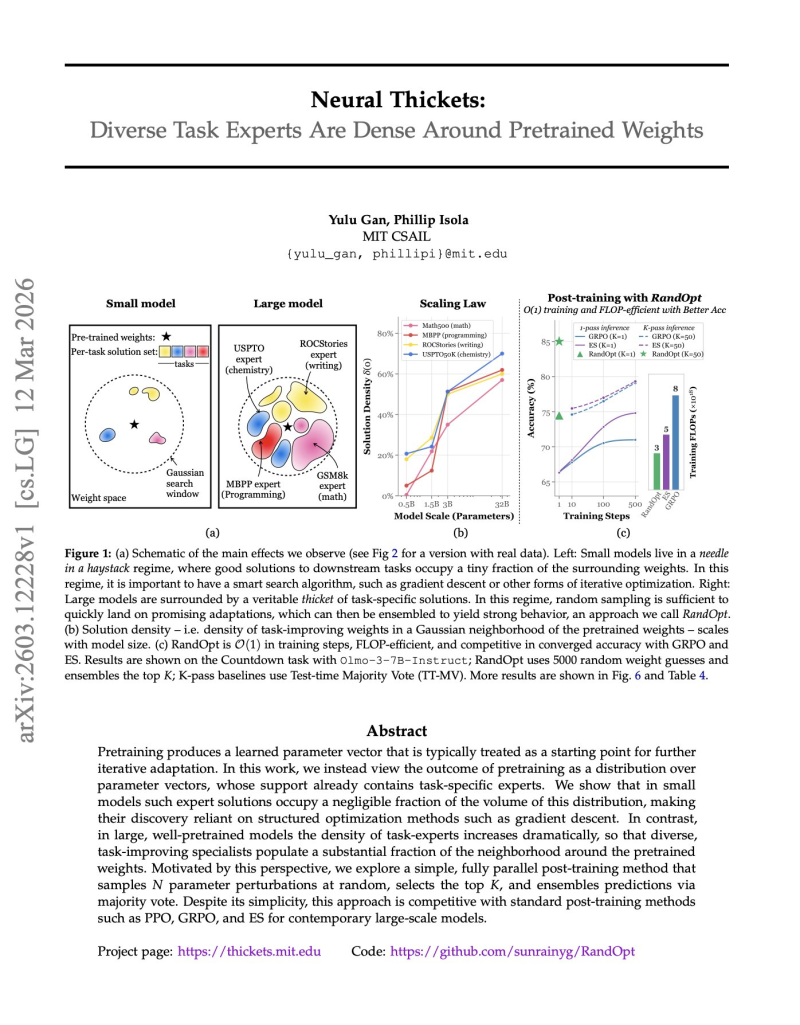
⬤ The central idea is what the researchers call "neural thickets" - a dense landscape of task-solving configurations clustered around pretrained weights. In smaller models, useful solutions are sparse and hard to find, making optimization heavily dependent on structured techniques like gradient descent. But as AI researchers explore ways to cut LLM training costs by up to 73%, this research adds another angle: in large models, task-capable parameter configurations multiply dramatically, forming a rich neighborhood of potential solutions that align with known neural scaling laws.
⬤ To test this idea, the team built a method called RandOpt - an approach that samples random perturbations of pretrained weights in parallel, selects top performers, and ensembles their predictions. No sequential gradient updates required. The experiments showed RandOpt achieving competitive accuracy while staying computationally lean compared to established post-training methods like PPO or evolutionary strategies. It's a strong signal that large models may already contain many specialized solutions hiding within their parameter space.
⬤ The implications stretch beyond this single paper. If reasoning ability can be unlocked through synthetic, structured training rather than massive human-text corpora, the economics of AI development could shift significantly. That same logic drives parallel efforts like CAS's LightRetriever, which achieves 1000x faster LLM search by rethinking retrieval from the ground up. Together, these lines of research point toward a future where smarter architecture choices matter more than raw data scale.
 Eseandre Mordi
Eseandre Mordi


