 Peter Smith
Peter Smith

⬤ A new research framework called TAPPA is changing how we understand attention mechanics inside large language models. Short for Temporal Attention Pattern Predictability Analysis, it maps why AI models fixate on specific patterns during inference. The core insight: when consecutive queries stay highly similar, key-value cache patterns lock into stable diagonal structures that are easy to anticipate. As explored in AI System Screens 10 Trillion Drug-Protein Combinations in 24 Hours, infrastructure efficiency is now one of the defining challenges as model workloads continue to scale.
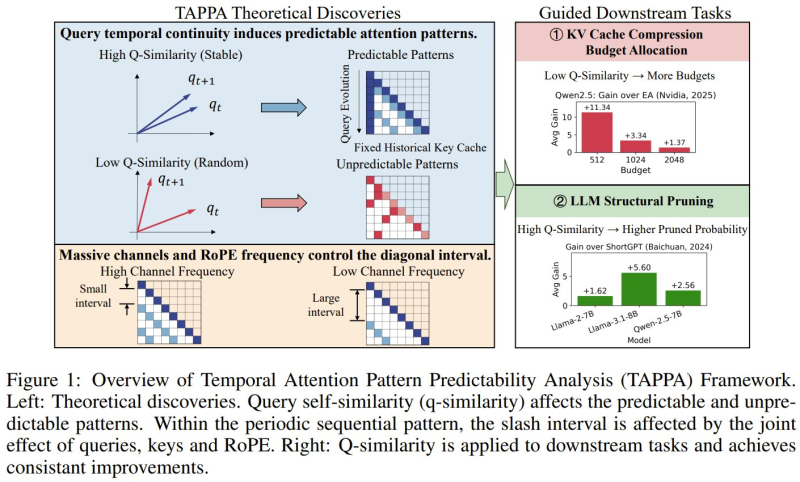
⬤ TAPPA also shows how positional encoding methods like RoPE and channel frequency jointly shape the spacing of attention patterns inside transformer networks. The implication: lower query similarity breaks those stable structures, producing irregular, harder-to-compress attention distributions. This connects directly to architectural choices in leaner models, as shown in Nanbeige-3B Model Scores 73.2 on ArenaHard, Outperforms Qwen, where optimized designs beat larger rivals through structural precision.
⬤ On the practical side, TAPPA introduces concrete optimization strategies. In KV cache compression tests, allocating more memory to low-similarity segments consistently outperformed baseline approaches. High-similarity regions, meanwhile, tolerated aggressive pruning with minimal accuracy loss. These methods were validated on Qwen and LLaMA-family architectures, offering a tested path toward leaner AI pipelines. Parallel efforts in AI-driven analysis are covered in Google Gemini Expands AI Stock Analysis With P/E Ratios, Earnings Reports, and Macro Scenarios.
⬤ The broader takeaway from TAPPA is that temporal attention predictability is not just a theoretical curiosity. It is a practical lever for cutting compute costs. By identifying where attention adds the most value, engineers can design systems that use memory and processing more strategically, without sacrificing output quality. The framework provides both a new theoretical lens and a workable roadmap for faster, cheaper transformer-based AI.
 Peter Smith
Peter Smith


