 Peter Smith
Peter Smith

Researchers from the Chinese Academy of Sciences (CAS) and Langboat Technology have introduced LightRetriever, a retrieval framework built to remove one of the most stubborn bottlenecks in modern AI-powered search: the cost of encoding queries in real time. As reported on X, the architecture is designed to make LLM-based search significantly faster without gutting the quality that makes large models worth using in the first place. Related shifts in computing demands are already reshaping hardware expectations, as covered in AI chip power demand surges toward 6000W.
How LightRetriever Cuts Query Latency by Over 1000x
In a conventional LLM retrieval pipeline, every incoming query goes through a full language model for tokenization and encoding before being matched against stored document embeddings. At scale, that process becomes a serious drag on throughput and response time.
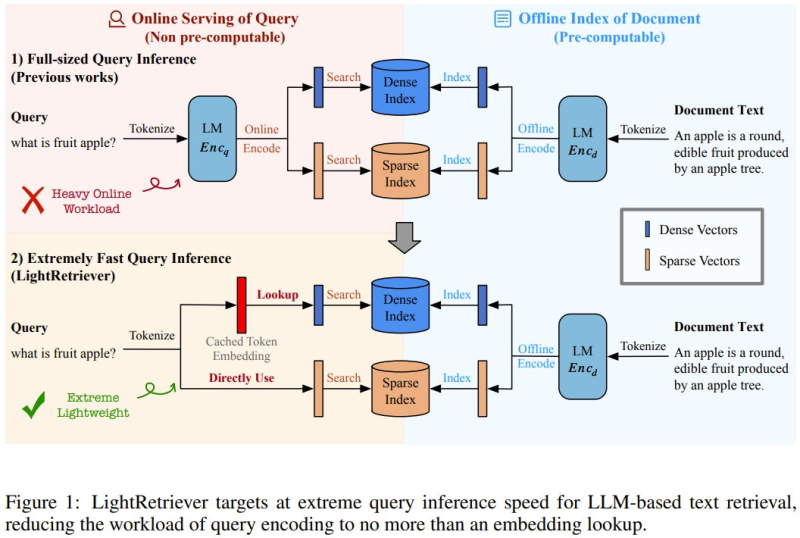
LightRetriever solves this by splitting the workload differently: the full LLM handles document encoding offline, while queries are matched using a lightweight cached token embedding lookup instead. The results speak for themselves - over 1000x faster query encoding and more than 10x higher end-to-end retrieval throughput, while still preserving roughly 95% of full-model performance across standard benchmarks.
Asymmetric Design That Keeps Accuracy Intact
What makes the architecture particularly clever is its asymmetry. Documents are pre-encoded and stored in dense or sparse vector indexes during an offline phase. At query time, the system skips the heavyweight model entirely and runs a fast embedding lookup instead. This design dramatically reduces runtime computation without meaningfully sacrificing retrieval accuracy - a tradeoff that has historically been difficult to strike cleanly. The broader race to benchmark and optimize LLM performance is playing out across the industry too, as seen in OpenAI's GPT-5.3 Codex scoring 79.3 on WeirdML benchmark, beating Opus 4.6.
The practical implications extend well beyond research benchmarks. Applications like enterprise knowledge retrieval, internal search engines, and large-scale document analysis all stand to benefit from faster query pipelines that don't require sacrificing model depth. As AI labs push the boundaries of what language models can do, infrastructure-level optimization like this is becoming just as important as model architecture itself - a point underscored by the recent wave of innovation covered in two Chinese tech giants quietly testing next-gen AI models in the public arena. LightRetriever makes a compelling case that smarter system design can deliver performance gains that rival raw compute scaling.
 Peter Smith
Peter Smith


