 Eseandre Mordi
Eseandre Mordi

A new Stanford research paper, Meta-Harness: End-to-End Optimization of Model Harnesses, highlights a shift in how AI systems are improved. As noted by Rohan Paul, instead of making the model itself smarter, the study demonstrates that optimizing the surrounding "harness" - the infrastructure that manages prompts, tools, and execution - can deliver substantial gains in performance.
The paper introduces Meta-Harness, a system that analyzes execution traces, source code, and prior runs to identify inefficiencies in how AI agents operate. On TerminalBench-2 with Claude Haiku 4.5, the optimized harness achieved 37.6%, outperforming Claude Code at 27.5%.
The improvements extend across tasks, including 48.6% versus 40.9% in text classification and 38.8% versus 34.1% in retrieval-augmented math.
Similar efficiency-focused approaches are explored in AI coding tool cuts Claude token use by 49x, where system-level changes significantly reduce resource usage.
How Meta-Harness Optimizes AI Performance Without Touching the Model
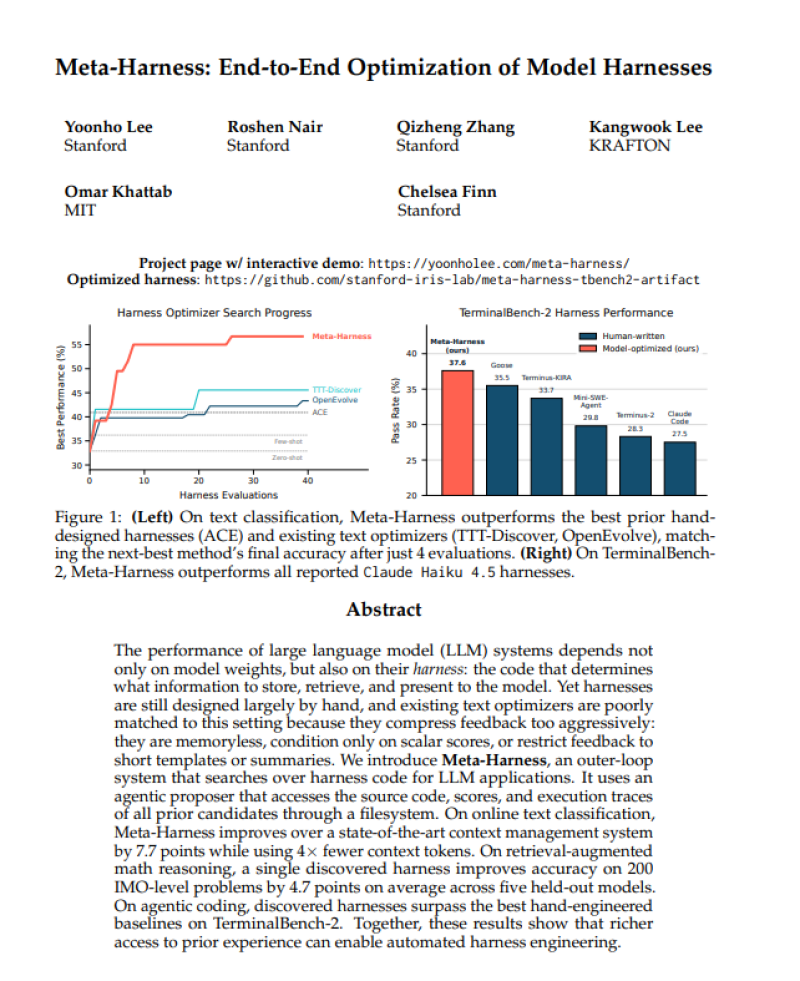
The key insight is that Meta-Harness does not retrain or modify the underlying model. Instead, it improves how the model interacts with its environment - how it processes tasks, selects tools, and determines completion.
Many failures originate in execution details such as timeouts, incorrect tool calls, or premature stopping, which are often hidden in raw logs.
The study emphasizes that by leveraging richer historical data, the system can diagnose issues more precisely - a concept aligned with frameworks discussed in new framework explains how 6-stage lifecycle makes large language models work.
Why System Architecture Drives AI Results
The results suggest that a significant portion of AI performance is tied to interface design rather than model capability alone. This reframing highlights the importance of system architecture in AI development, as broader datasets and structured context can unlock better outcomes without increasing model size.
Broader datasets and structured context can unlock better outcomes without increasing model size.
Related research such as Stanford's synthetic megadocs boost AI data efficiency by 18x further underscores how improvements outside core model training can drive measurable gains.
Key findings from the Meta-Harness study:
- TerminalBench-2: Meta-Harness at 37.6% vs. Claude Code at 27.5%
- Text classification: 48.6% vs. 40.9%
- Retrieval-augmented math: 38.8% vs. 34.1%
- No retraining or model modification required
- Gains achieved by analyzing execution traces, source code, and prior runs
 Eseandre Mordi
Eseandre Mordi


