 Marina Lyubimova
Marina Lyubimova

Most AI labs treat training data like a fixed resource. Stanford researchers are now challenging that assumption. A new study from Stanford University introduces a method of scaling synthetic "megadocs" during pre-training, demonstrating measurable improvements in data efficiency without requiring additional real-world data.
How Megadocs Cut Loss on Real Data by 1.8x
The paper, titled "Data-efficient pre-training by scaling synthetic megadocs," tests several approaches to synthetic data generation, including simple rephrasing, stitched rephrasing, and latent thought generation. Real-data-only training establishes a baseline loss of roughly 3.55. Scaled synthetic methods bring that figure down to around 3.34, with robot AI co-training models cutting data costs pointing to similar trends across the industry. Among all tested techniques, latent thought generation achieves the lowest loss as generation volume increases.
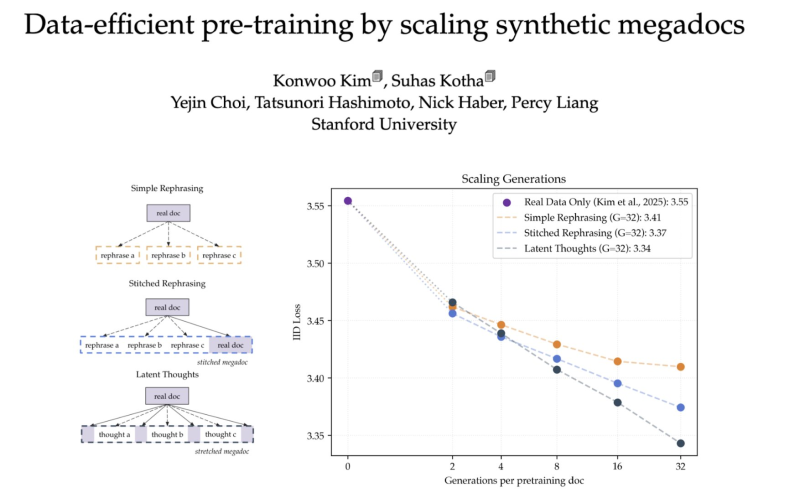
The core innovation is grouping multiple synthetic generations into a single extended document, or "megadoc," rather than treating each generation as an isolated training sample. This structure allows models to extract richer signal from the same source material. The result is up to a 1.8x improvement in data efficiency, with larger gains as compute scales up.
Scaling Synthetic Data as a Core Training Strategy
The findings arrive as the broader AI industry accelerates its pivot toward synthetic data pipelines. Perplexity AI's computer integration growth reflects a sector increasingly reliant on high-volume, efficiently generated training signals. Reducing dependence on scarce real-world data is no longer a secondary concern; it is becoming a primary engineering goal.
The labor implications are equally significant. A recent Anthropic report on AI exposure in programming jobs found that 74.5% of programming roles face high AI exposure, reinforcing how advances in training efficiency connect directly to workforce transformation. As synthetic data methods mature, the cost curve for building capable models continues to shift downward.
 Marina Lyubimova
Marina Lyubimova


