 Eseandre Mordi
Eseandre Mordi

Meta has introduced a new vision backbone called the Efficient Universal Perception Encoder, purpose-built for deployment on edge devices. As reported by DailyPapers, the model is now available on Hugging Face and brings together image understanding, vision-language modeling, and dense prediction inside a single unified architecture.
Multi-Teacher Distillation Powers the Efficient Universal Perception Encoder
At the heart of the framework is a multi-teacher distillation approach. Rather than training a model from scratch on individual tasks, knowledge from several high-performing teacher models is compressed into one compact system.
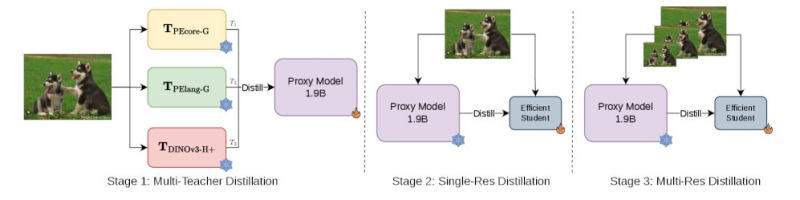
The process moves through structured stages - beginning with multi-teacher distillation, followed by iterative refinement - allowing the model to absorb capabilities from different vision domains without requiring separate architectures for each.
The distillation pipeline lets a single compact model inherit the strengths of multiple specialized teachers, without carrying the full inference cost of any of them.
This reflects broader progress in efficient AI, as seen in open-source AI models closing performance gaps with their larger counterparts.
1 Backbone for All Vision Tasks on Edge Devices
The Efficient Universal Perception Encoder consolidates multiple visual tasks into a single backbone, removing the need to run and maintain separate specialized models side by side. For edge devices where compute and memory are tightly constrained, this matters a great deal. Fewer models in the pipeline means lower latency, reduced memory footprint, and simpler deployment. The approach aligns with the current direction across the AI industry, including efforts like Grok-4 pushing efficient reasoning boundaries with a leaner inference profile.
The key capabilities unified within a single backbone include:
- Image understanding and classification
- Vision-language modeling
- Dense prediction tasks such as segmentation and depth estimation
Edge AI Demand Is Driving Compact and Versatile Model Design
The release arrives at a moment when demand for lightweight, multi-purpose AI is accelerating. As AI systems move into embedded hardware, IoT devices, and on-device applications, the ability to run a single model across diverse vision tasks becomes a real competitive advantage.
The demand for compact, multi-task models is not slowing down. As AI moves deeper into edge hardware, approaches that reduce model fragmentation will define the next generation of deployable systems.
Broader industry frameworks addressing AI system risks and rare events also point toward this shift - less fragmentation, more generalization, and architectures that hold up in unpredictable real-world conditions.
 Eseandre Mordi
Eseandre Mordi


