 Victoria Bazir
Victoria Bazir

Artificial intelligence benchmarking hit an interesting milestone this week when xAI's Grok-4 (Fast Reasoning) showed impressive performance on the ARC-AGI semi-private leaderboard. What makes this noteworthy isn't just the scores themselves, but how efficiently the model achieved them. Grok-4 is proving that the path to artificial general intelligence doesn't necessarily require massive computational budgets.
ARC-AGI Benchmarks: Testing Real Machine Reasoning
The Abstraction and Reasoning Corpus, known as the ARC Prize, stands out as one of AI research's toughest challenges. Unlike conventional tests that favor memorization or sheer scale, it evaluates whether a model can grasp abstract patterns, adapt rules on the fly, and generalize knowledge across contexts—the hallmarks of human-like reasoning.
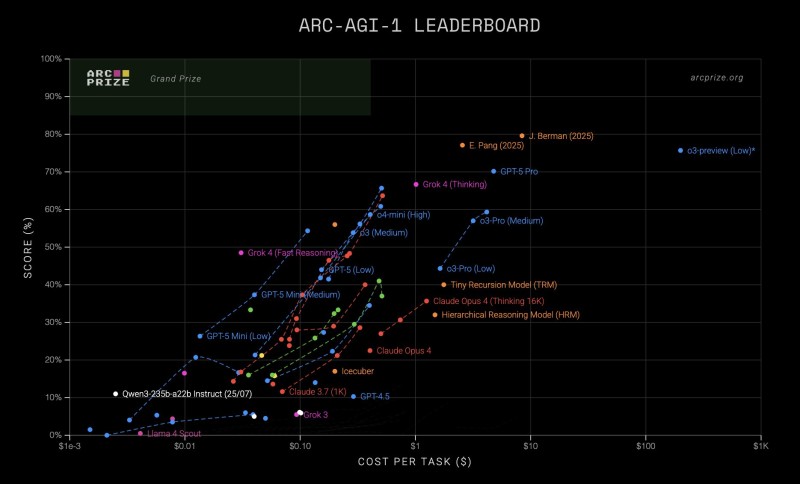
Grok-4's results speak for themselves. On the ARC-AGI-1 leaderboard, the model hit 48.5% accuracy at just $0.03 per task, delivering one of the best cost-to-accuracy ratios in the field.
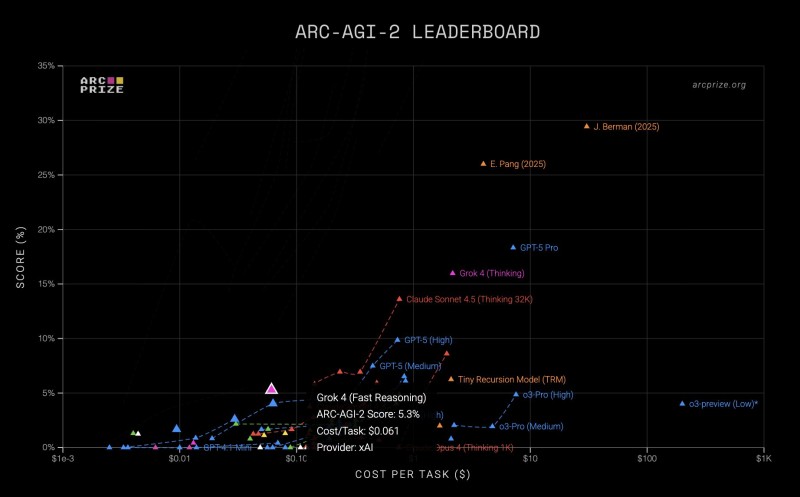
The harder ARC-AGI-2 benchmark, which tests multi-step reasoning, saw Grok-4 score 5.3% at $0.06 per task. These numbers put it alongside heavyweights like GPT-5 Pro and Claude Sonnet 4.5, but with dramatically lower computational costs.
Performance That Makes Economic Sense
Looking at the leaderboard data, Grok-4 occupies a sweet spot on the cost-performance curve—delivering nearly half of full reasoning capability at remarkably low expense. Other top-tier models like o3-Pro, Claude Opus 4, and GPT-5 Pro achieve similar accuracy but burn through 10 to 100 times more computation per task.
This isn't about cutting corners. It reflects a different design philosophy: optimizing for reasoning efficiency rather than endlessly scaling model size. Grok-4's architecture focuses on fast inference and structured cognitive processes, producing analytical patterns similar to human reasoning without the computational overhead.
The implications extend beyond technical benchmarks. As AI moves into real-time applications across business, education, and research, models that reason effectively without requiring massive infrastructure will lead the next adoption wave. For xAI, this milestone confirms that advanced reasoning doesn't require trillion-parameter models, and suggests that AGI development may ultimately depend more on cognitive precision per dollar than raw scale.
 Victoria Bazir
Victoria Bazir


