 Saad Ullah
Saad Ullah

Most text-to-speech systems today still rely on intermediate stages - converting text to phonemes, phonemes to spectrograms, and spectrograms to audio. Each handoff introduces small errors that stack up and degrade the final output. Meituan's new model takes a different path entirely, generating audio directly in waveform latent space and cutting out the middle steps that have long been a weak point in diffusion-based TTS.
Meituan's LongCat-AudioDiT Skips the Spectrogram Step
Most text-to-speech systems today still rely on intermediate stages - converting text to phonemes, phonemes to spectrograms, and spectrograms to audio. Each handoff introduces small errors that stack up and degrade the final output.
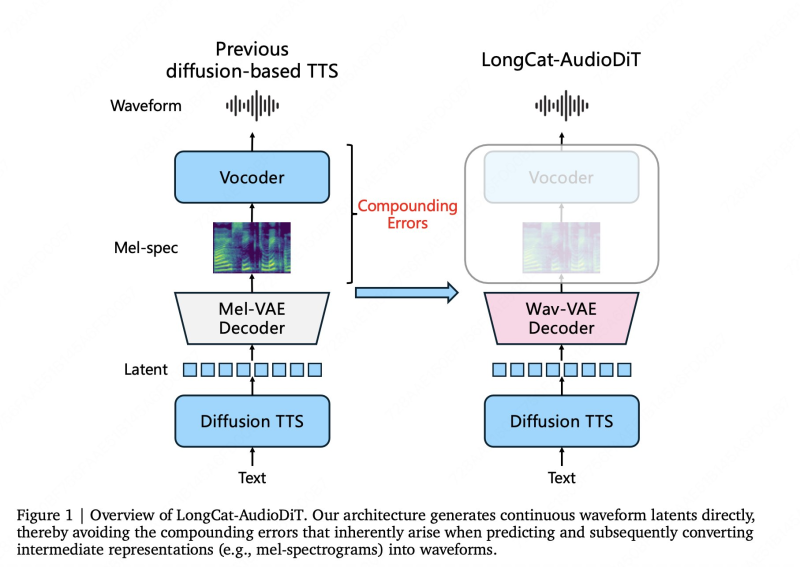
Meituan's new model takes a different path entirely, generating audio directly in waveform latent space and cutting out the middle steps that have long been a weak point in diffusion-based TTS.Meituan has introduced LongCat-AudioDiT, a diffusion-based text-to-speech (TTS) model designed to operate directly in waveform latent space. As reported by Meituan LongCat, the system removes the need for intermediate representations such as mel-spectrograms, aiming to reduce compounding errors in speech generation and improve output quality.
This architecture simplifies the TTS pipeline and improves synthesis by avoiding error accumulation seen in traditional diffusion-based TTS systems.
The model uses a non-autoregressive diffusion-based pipeline combined with a Wav-VAE decoder, enabling direct waveform generation.
This approach simplifies the overall TTS pipeline and reduces the kind of error accumulation that typically builds up across multi-stage systems. LongCat-AudioDiT is available in two sizes - 1B and 3.5B parameters - and supports multilingual audio generation across Chinese and English.
LongCat-AudioDiT Voice Cloning Scores 0.818 on Seed-ZH Benchmark
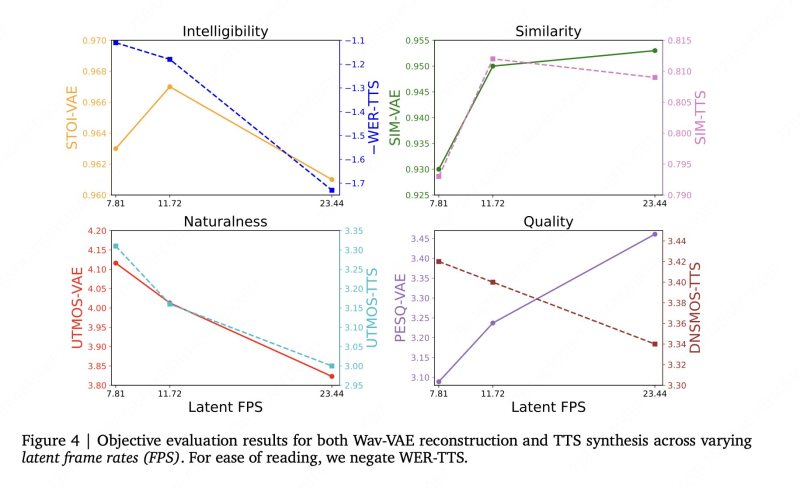
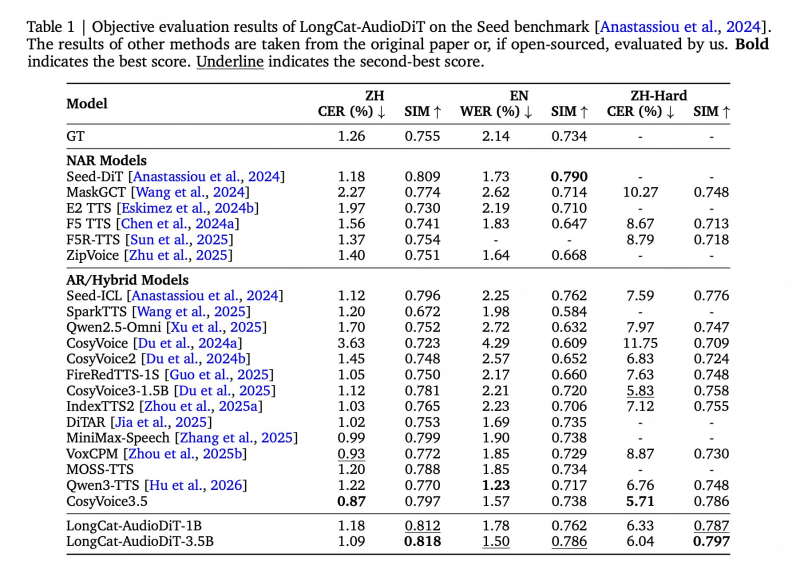
LongCat-AudioDiT achieves strong results in voice cloning benchmarks, with similarity scores of 0.818 on Seed-ZH and 0.797 on Seed-Hard datasets.
The framework also introduces an APG-based approach to replace traditional classifier-free guidance, which improves perceived naturalness and acoustic quality in output audio. This aligns with broader efficiency trends in AI infrastructure, such as AI models generating 5-second video in 2 seconds on H100.
By simplifying architecture and improving output quality, waveform-based diffusion models may influence future developments in voice AI.
Key technical improvements in LongCat-AudioDiT include:
- Direct waveform generation via Wav-VAE decoder, removing spectrogram intermediaries
- APG-based guidance replacing classifier-free guidance for better naturalness
- Non-autoregressive diffusion pipeline reducing sequential generation errors
- Bilingual support covering Chinese and English in a single model
- Scalable architecture available at 1B and 3.5B parameter sizes
The model also directly tackles the training-inference mismatch that commonly shows up in diffusion-based TTS systems. These advances reflect the broader push toward high-fidelity, efficient speech generation - a trend also visible in areas like emotion-aware AI systems in robotics, where architectural simplicity is increasingly seen as a competitive edge.
Waveform Diffusion Models Could Shape the Future of Voice AI
The release of LongCat-AudioDiT underscores the growing industry focus on cleaner, more efficient model architectures for speech.By working directly in waveform latent space, the system sidesteps one of the core bottlenecks in traditional pipelines.
The release highlights increasing focus on high-fidelity and efficient speech generation as AI systems scale.
Wider momentum behind efficient AI design, including developments like the DeepSeek V4 launch shifting attention to AI chips, signals that architectural efficiency is becoming a competitive priority across global AI markets.
 Saad Ullah
Saad Ullah


