 Saad Ullah
Saad Ullah

⬤ New research puts a number on something AI developers have long suspected: alignment pulls language models away from how people actually behave. The study compares 120 base and aligned model pairs across more than 10,000 human decisions in strategic settings. The conclusion is blunt - aligned models tend to predict what humans should do, not what they actually do.
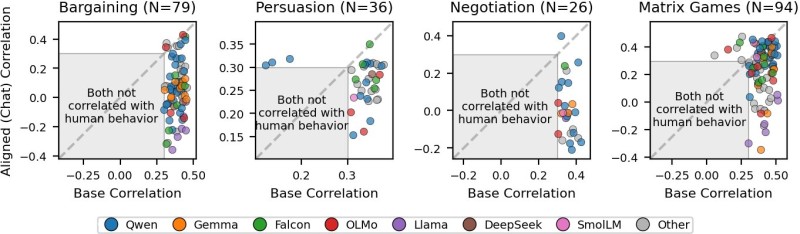
⬤ In head-to-head tests covering bargaining, persuasion, negotiation, and matrix-style games, base models outperform aligned versions at a ratio of nearly 10 to 1. Correlation charts show base models tracking real human behavior closely, while aligned counterparts routinely land in zones marked "not correlated." The gap is not marginal - it's systematic. And as AI job growth in roles most exposed to language models climbed 93% since ChatGPT's launch, the stakes of getting model behavior right keep rising.
⬤ The dataset covers a wide range of architectures - Qwen, Gemma, Falcon, Llama, DeepSeek, and more - with sample sizes between 26 and 94 observations per task. The pattern holds across all of them. That consistency makes it hard to dismiss as a quirk of any single model family. It also lands at an interesting moment: DeepSeek V4-lite recently scored 2nd place among all Chinese AI models, a reminder that competitive performance is accelerating even as these behavioral gaps remain unresolved.
⬤ The takeaway is structural, not incidental. Alignment and behavioral accuracy appear to trade off against each other, and that tension will only matter more as models get embedded in real-world decision environments. Progress elsewhere in the ecosystem - like Google DeepMind releasing Gemma Scope 2 tools across all 270M to 27B parameter models - shows the field is moving fast. But if aligned models can't reliably reflect human behavior, developers and researchers need to understand exactly where that misalignment begins.
 Saad Ullah
Saad Ullah


