 Usman Salis
Usman Salis

⬤ Google DeepMind rolled out the FACTS Benchmark Suite—a fresh evaluation system that measures how factually accurate large language models really are. The benchmark tests four key areas: grounding on long documents, multimodal reasoning, search-enhanced answers, and parametric knowledge stored in the model itself. It uses 3,513 handpicked examples plus a private test set to score performance. Right out of the gate, Gemini 3 Pro landed at number one.
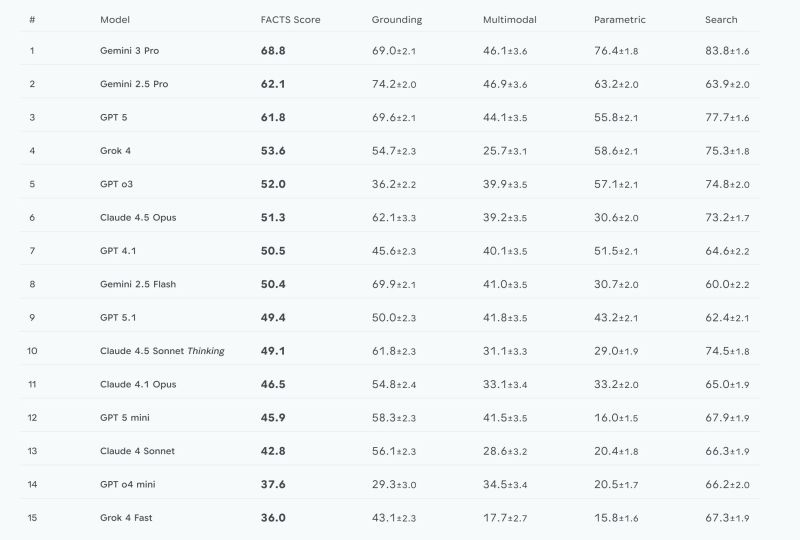
⬤ The results show Gemini 3 Pro hitting a 68.8% FACTS Score overall, with particularly strong numbers in search (83.8) and parametric knowledge (76.4), while grounding came in at 69.0 and multimodal tasks at 46.1. Google says this version slashed error rates by 55% on search tasks and 35% on parametric questions compared to its predecessor, Gemini 2.5 Pro, which scored 62.1%. That's real progress, though even the best system is still sitting below 70% accuracy—meaning there's plenty of room left to improve.
⬤ The competition's heating up fast. GPT 5 grabbed a 61.8 FACTS Score, Grok 4 pulled 53.6, and GPT o3 landed at 52.0. Claude 4.5 Opus, GPT 4.1, and Gemini 2.5 Flash all clustered around the 50-point mark, while GPT 5.1 and Claude 4.5 Sonnet Thinking came in just below. Further down the rankings, GPT 5 mini scored 45.9, Claude 4 Sonnet hit 42.8, GPT o4 mini managed 37.6, and Grok 4 Fast brought up the rear at 36.0. The spread makes it clear that factual hallucinations are still a major problem across the board.

⬤ The launch of the FACTS Benchmark Suite signals a shift toward tougher, more transparent testing as AI models take on increasingly complex real-world tasks. Gemini 3 Pro's lead gives Google serious momentum in factual reasoning and retrieval performance, raising the bar for rivals—including the upcoming GPT-5.2—to chase. This benchmark looks set to become the go-to standard for measuring accuracy and reliability in the next wave of AI models.
 Usman Salis
Usman Salis


