 Artem Voloskovets
Artem Voloskovets

⬤ China's GLM-5 is back in the spotlight after fresh benchmark comparisons put it shoulder-to-shoulder with some of the biggest names in AI. GLM-5 landed a score of 50 on the Artificial Analysis Index, with results charted against Claude Opus 4.5, Gemini 3 Pro, GPT-5.2, and GLM-4.7 across eight benchmark suites covering reasoning, multilingual ability, coding, and agentic tasks.
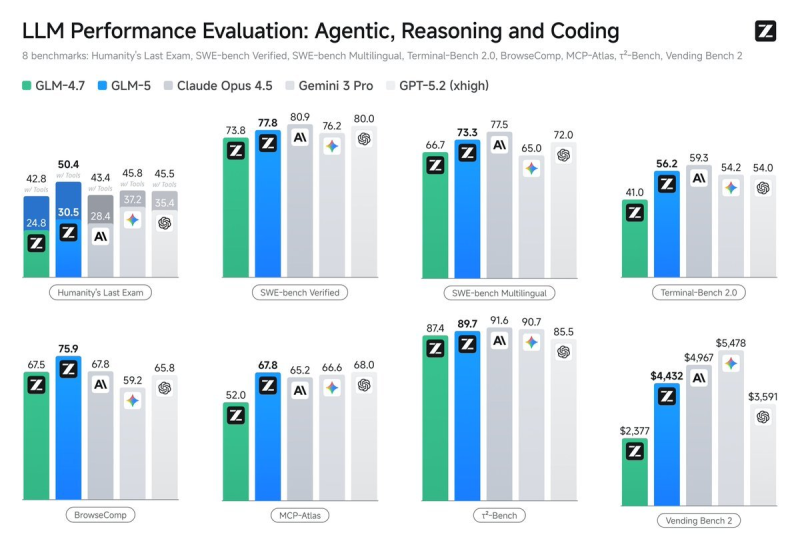
⬤ Dig into the numbers and the picture gets more interesting. GLM-5 scored 89.7 on T2-Bench, just behind Claude Opus 4.5 (91.6) and close to Gemini 3 Pro (90.7). On SWE-bench Verified it hit 77.8, sitting comfortably between its peers and showing solid multilingual reasoning. Coding is where things split: GLM-5 achieved a coding score of 7,364 and beat GPT-5.1 Codex on LiveBench tasks, yet in other real-world environments it trailed by 186 points. That gap between synthetic and practical benchmarks is a recurring theme across the industry.
Model ranking can shift significantly depending on the benchmark methodology - aggregate scores rarely capture the full picture.
⬤ The broader sweep of results tells a similar story. On Terminal-Bench 2.0 and MCP-Atlas, GLM-5 tracked closely with established frontier models, reinforcing its profile as a capable generalist. In multilingual tests it competed well globally, and on Vending Bench 2 it placed respectably next to Gemini 3 Pro and GPT-5.2. Overall, GLM-5 trails by 186 points in real-world coding benchmarks even as it leads in others - proof that context matters as much as the number itself.
⬤ These mixed results are a useful reminder that AI comparisons live and die by the task type, evaluation framework, and operational context. As OpenAI, Anthropic, and Chinese developers keep pushing the pace, performance gaps in coding, reasoning, and agentic work will keep shifting. For organizations making real deployment decisions, use-case fit matters far more than chasing a top aggregate ranking.
 Artem Voloskovets
Artem Voloskovets


